사건의 연관규칙을 찾아내는 연관분석에 대해서 정리해 보자.
이 전글에선 군집분석 중에서 비계층적 군집분석(K-means, 혼합분포)에 대해서 정리하며 다뤄보았다.
군집분석(Clustering) - 비계층적 군집분석
각 객체의 유사성을 측정해서 유사성이 높은 대상집단을 분류하는 군집분석을 정리해 보자. 계층적 군집분석은 저번에 정리해 보았다. 군집분석(Clustering) - 계층적 군집분석 각 객체의 유사성을
py-moon.tistory.com
연관분석은 소비자의 행동패턴을 사건의 연관규칙으로 분석하기도 한다.
인스타, 유튜브, OTT플랫폼에서 알고리즘으로 인한 추천 게시물을 받아본 적이 있을 것이다.
이처럼 게시물을 추천해 주는 알고리즘의 기반이 되는 연관분석의 개념 중 지지도(Support), 신뢰도(Confidence), 향상도(Lift)에 대해서도 정리하고자 한다.
먼저, Run-Test를 진행해 보자.
Run-Test는 "연관규칙을 찾기 전에" 연속적인 이진 값들의 연관성 여부를 검정하는 기법이다.
|
1
2
3
4
|
import pandas as pd
data = ['a', 'a', 'b', 'b', 'a', 'a', 'a', 'a', 'b', 'b', 'b', 'b', 'b', 'a', 'a', 'b', 'b', 'a', 'b', 'b']
test_df = pd.DataFrame(data, columns = ['product'])
|
cs |
> Run-Test를 진행하기 전, 간단하게 실습해 볼 데이터를 가져온 후 Dataframe으로 변환해 준다.
> 상품 a와 상품 b의 구매패턴을 보여주는 데이터이다.
|
1
2
3
4
|
from statsmodels.sandbox.stats.runs import runstest_1samp
test_df.loc[test_df['product']=='a', 'product'] = 1
test_df.loc[test_df['product']=='b', 'product'] = 0
|
cs |
> 런 검정을 진행하기 위해 a와 b를 0과 1로 이루어진 이진 데이터로 변환해 준다.
> 우리는 여기서 가설을 하나 세울 수 있다.
귀무가설 : 연속적인 관측값이 임의적이다.
대립가설 : 연속적인 관측값이 서로 연관이 있다.
|
1
2
3
|
runstest_1samp(test_df['product'], cutoff = 0.5, correction = True)
(-1.1144881152070183, 0.26506984027306035)
|
cs |
> 런 검정을 진행한 결과 유의확률(pvalue)이 약 0.26으로 유의 수준(0.05) 보다 높으므로 귀무가설 채택한다.
> 즉, 상품 a와 b의 구매에는 연관이 없다는 결과이다.
다음으로 연관규칙분석으로 넘어가 보자.
우선, 연관규칙분석에 사용되는 척도에 대해 간단히 짚어보자.
1. 지지도(Support)
전체 거래 중에서 A항목과 B항목으로 동시에 포함하는 거래의 비율을 정의한다.
쉽게 말해, 높을수록 좋다
2. 신뢰도(Confidence)
A항목을 포함한 거래 중에서 A항목과 B항목이 같이 포함될 확률로 연관성의 정도를 파악할 수 있다.
쉽게 말해, 높을수록 좋다.
3. 향상도(Lift)
A항목이 구매되지 않았을 때 B항목의 구매확률에 비해 A항목이 구매되었을 때 B항목의 구매확률의 증가 비율로 정의한다.
A항목과 B항목 간에 대략적인 관계를 파악할 수 있다.
쉽게 말해서 1이면 서로 독립적인 관계,
1보다 크면 두 품목이 서로 양의 상관관계,
1보다 작으면 두 품목이 서로 음의 상관관계를 가진다는 말이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder
dataset = [['Apple', 'Beer', 'Rice', 'Chicken'],
['Apple', 'Beer', 'Rice'],
['Apple', 'Beer'],
['Apple', 'Bananas'],
['Milk', 'Beer', 'Rice', 'Chicken'],
['Milk', 'Beer', 'Rice'],
['Milk', 'Beer'],
['Apple', 'Bananas']]
te = TransactionEncoder()
te_ary = te.fit_transform(dataset)
|
cs |
> 연관규칙분석을 진행하기 위해 데이터를 가지고 온다.
> TransactionEncoder를 통해서 True(구매), False(비구매) 형태로 변환해 준다.
|
1
|
df = pd.DataFrame(te_ary, columns = te.columns_)
|
cs |
> 분석을 위해 DataFrame으로 변환한 후 head()를 찍어보았다.
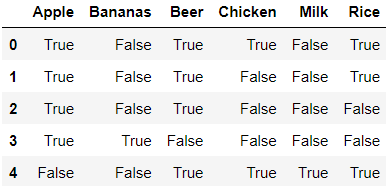
> 위와 같은 형태로 데이터가 변환이 되었고 DataFrame으로 변환된 모습을 확인할 수 있다.
> 이 데이터를 가지고 Apriori알고리즘으로 연관규칙분석을 진행해 보자.
|
1
2
3
|
from mlxtend.frequent_patterns import apriori
apriori(df, min_support = 0.6, use_colnames = True)
|
cs |
> 코드에 min_support=0.6이라는 부분이 있는데 이것은 최소 지지도가 60% 이상인 품목을 추출하겠다는 뜻이다.

> 결과를 확인해 보면 위처럼 지지도와 품목을 보여주고 있다.
> 해석하자면, 사과와 맥주는 전체 거래 중 60% 이상 포함되어 있다고 볼 수 있다.
|
1
2
|
frequent_itemsets = apriori(df, min_support = 0.3, use_colnames = True)
frequent_itemsets['length'] = frequent_itemsets['itemsets'].apply(lambda x: len(x))
|
cs |
> 또한, 지지도와 더불어 품목의 개수와 함께 추출할 수도 있다.
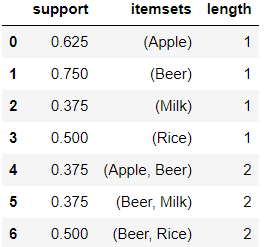
> 이번 결과는 최소 지지도가 30% 이상인 품목과 품목의 개수를 함께 보여주고 있다.
이번에는 Groceries데이터셋을 통해 실습을 진행해 보자.

> 데이터를 불러오고 head()를 찍어보니 앞서 진행한 실습과는 차원이 다른, 많은 품목들을 보여주고 있다.
> 중간에 쉼표로 구분된 것을 포함해서 전처리해야 하는 부분이 있지만, 알고자 하는 것이 위 실습과 같다면 쫄지말고 동일하게 진행하면 된다.
|
1
|
df_split = df.iloc[:,0].str.split(',', expand = True)
|
cs |
> 쉼표를 기준으로 품목들을 구분해 주는 과정이다.

> 데이터가 너무 길어 상위 세 거래만을 보면 결과는 이러하다.
|
1
2
3
4
5
|
df_split_ary = df_split.values
groceries = []
for i in range(len(df_split_ary)):
temp = list(filter(None, df_split_ary[i]))
groceries.append(temp)
|
cs |
> 하지만, 보이듯이 None값들이 들어가 있다. 위 코드는 None값들을 지워주는 과정이다.

> None값을 제거한 결과는 위와 같다.
> 이제 이 데이터를 가지고 연관규칙분석을 진행해 보자.
|
1
2
3
4
5
6
|
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder
te = TransactionEncoder()
groceries_tr = te.fit_transform(groceries)
groceries_tr = pd.DataFrame(groceries_tr, columns = te.columns_)
|
cs |
> 해당 데이터를 True(구매), False(비구매) 형태로 변환한 후 Dataframe으로 변환하였다.
|
1
2
3
|
from mlxtend.frequent_patterns import apriori
groceries_ap = apriori(groceries_tr, min_support = 0.01, use_colnames = True)
|
cs |
> 이번에는 최소 지지도가 1% 이상인 빈번항목집합을 추출해보았다.

> 결과 중 상위 5개만 추려보았다. 잘 뽑힌 것을 확인할 수 있다.
> 하지만, 지지도와 항목만을 보기에는 좀 부족하다. association_rules함수를 활용해서 더 많은 규칙을 확인해보자.
|
1
2
3
|
from mlxtend.frequent_patterns import association_rules
association_rules(groceries_ap, metric = 'confidence', min_threshold = 0.3)
|
cs |
> association_rules()를 활용해서 이번에는 신뢰도가 0.3이상인 빈번항목집합을 추출해보았다.

> 결과를 확인해보니 지지도, 신뢰도, 향상도 이외에도 많은 규칙들을 확인할 수 있다.
> 애초에 조건을 걸어서 출력하도록하면 필요한 자료를 효율적으로 뽑아볼 수 있다.
|
1
2
3
4
|
rules = association_rules(groceries_ap, metric = 'lift', min_threshold = 1)
rules['antecedent_len'] = rules['antecedents'].apply(lambda x: len(x))
rules[(rules['antecedent_len'] >= 2) & (rules['confidence'] >= 0.4) & (rules['lift'] >= 3)]
|
cs |
> 조건을 걸어보았는데 해석하자면, 향상도가 1 이상인 빈번항목들을 추출한다.
> 추출한 항목에서 항목의 개수가 2개 이상이고, 신뢰도가 0.4이상이고 향상도가 3이상인 항목만을 추출하게 하였다.

> 결과는 두 거래가 추출되었다.
> 이렇게 집합연산을 사용해서 조건을 걸어주면 필요없는 자료는 걸러내고 필요한 정보만을 볼 수 있다는 장점을 가지고 있다.
OUTTRO.
아직 상품판매 관련 데이터셋으로 분석과제를 수행한 적은 없지만 상품에 대한 구매규칙을 찾기에 연관분석이 용이하게 쓰일 듯하다.
특히, 향상도(Lift)는 품목간에 관계를 알 수 있다는점이 다방면으로 유용할 듯하다.
온/오프라인으로 상품판매를 서비스하는 기업에서 사용하는 필수적인 분석방법이 아닐까하는 생각에 좀 더 연구해봐야겠다는 생각이 든다.
TransactionEncoder와 association_rules, apriori함수들을 처음 사용하면서 분석과제를 할 때 쓰면 좋겠다는 생각이 든다.
최근 통계분석에 빠져서 분석과제에 소홀했는데 다음 글에서 정리할 시계열 분석까지 마무리하고나서 다시 분석과제를 다뤄보고자 한다.
'내가 하는 데이터분석 > 내가 하는 통계분석' 카테고리의 다른 글
| [시계열 분석, Timeseries Analysis] - AR, MA, ARIMA with Python (0) | 2023.01.28 |
|---|---|
| [시계열 분석, Timeseries Analysis] - 시계열 분해, 정상성 with Python (0) | 2023.01.20 |
| [군집분석, Clustering] - 비계층적 군집분석 with Python (4) | 2023.01.16 |
| [군집분석, Clustering] - 계층적 군집분석 with Python (0) | 2023.01.14 |
| [교차분석, ChiSquare Test] with Python (0) | 2023.01.12 |



