이번엔시간의 흐름에 따라 기록된 데이터를 바탕으로 미래의 변화에 대한 추세를 분석방법인 시계열 분석을 다뤄보자.
이 전글에서 연관분석(지지도, 신뢰도, 향상도)에 대해서 다뤄보며 정리해 봤다.
연관분석(Association Analysis) with Python
사건의 연관규칙을 찾아내는 연관분석에 대해서 정리해 보자. 이 전글에선 군집분석 중에서 비계층적 군집분석(K-means, 혼합분포)에 대해서 정리하며 다뤄보았다. 군집분석(Clustering) - 비계층적
py-moon.tistory.com
시계열 분석 안에서 시계열 분해는 추세(Trend), 계절성(Seasonality), 잔차(Residual)로 분해하는 기법이다.
여기서 추세와 계절성은 시간의 요인이고, 잔차(불규칙요인)는 외부요인이다.
arima_data를 활용해서 시계열 분해를 직접 실습해 보자.
|
1
2
3
4
|
import pandas as pd
import warnings
data = pd.read_csv('data/arima_data.csv', names = ['day', 'price'])
|
cs |
> 시계열 분해를 위한 arima_data를 불러오면서 day변수와 price변수만을 가져온다.
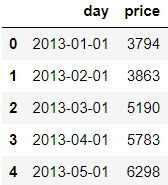
> head()를 통해서 데이터 일부를 확인해 본 결과이다.
> 하지만, day변수가 object문자열이므로 분석을 위해 datetime자료형으로 변환한다.
|
1
2
|
data['day'] = pd.to_datetime(data['day'], format="%Y-%m-%d")
data.set_index('day', inplace=True)
|
cs |
> pd.to_datetime()을 활용하면 한 줄만으로 object문자열을 datetime자료형으로 변환할 수 있다.
> 자료형을 변환함으로써 분석에 쓰일 준비는 끝났다.
|
1
2
3
|
import matplotlib.pyplot as plt
plt.plot(data.index, data['price'])
|
cs |
> 데이터를 시각화해서 시계열 분해를 진행해 보자.
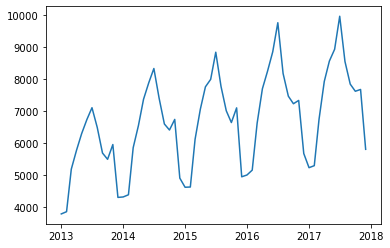
> 시각화한 결과를 확인해 보면 추세에 따라 계절성이 존재하는 것을 확인할 수 있다.
> 또한, 시간이 지날수록 그 변동이 점점 커지고 있음을 알 수 있다.
|
1
2
3
4
5
6
|
from statsmodels.tsa.seasonal import seasonal_decompose
result = seasonal_decompose(data, model = 'multiplicative')
plt.rcParams['figure.figsize'] = [12, 8]
result.plot()
plt.show()
|
cs |
> 우리는 위 그래프를 각 요인별로 쪼개어서 확인해보고자 한다.

> 위에서부터 원본, 추세, 계절성, 잔차 순으로 요인별로 시계열 분해를 해준 결과이다.
> 해당 데이터는 추세와 계절성이 명확히 존재하는 것과 잔차는 거의 없음을 확인할 수 있다.
> 즉, 정상성에 위배되었기 때문에 정상 시계열이 아니라는 것도 알 수 있다.
정상성 변환
정상성이란 시간에 따라 평균, 분산이 일정한 성질을 가지고 있다는 것이다.
이후에 ARIMA모형에 적용시키기 위해 데이터가 정상성을 만족해야 한다.
정상성을 검정하기 위해서는 Augmented Dickey-Fuller Test를 진행한다.
|
1
2
3
4
5
6
7
8
|
from statsmodels.tsa.stattools import adfuller
training = data[:'2016-12-01']
test = data.drop(training.index)
adf = adfuller(training, regression='ct')
print('ADF Statistic : {}'.format(adf[0]))
print('p-value : {}'.format(adf[1]))
|
cs |
> 결과 해석에 용이하도록 데이터를 train과 test로 분리한 후 adfuller() 함수를 통해서 정상성을 검정한다.
> 정상성 검정에 사용되는 가설은 아래와 같다.
귀무가설 : 해당 데이터가 정상성을 갖지 않는다.
대립가설 : 해당 데이터가 정상성을 갖는다.
|
1
2
|
ADF Statistic : -1.9997199341328131
p-value : 0.6015863303793997
|
cs |
> 결과를 해석하면, 유의확률(p-value)이 약 0.6으로 유의 수준(0.05) 보다 높으므로 귀무가설 채택한다.
> 즉, 해당 데이터는 정상성을 갖지 않는다고 할 수 있다.
|
1
2
3
4
5
|
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
diff_data = training.diff(1)
diff_data = diff_data.dropna()
diff_data.plot()
|
cs |
> 해당 데이터를 정상시계열로 변환시키기 위해 1차 차분을 진행하고, 결측치를 제거해 준다.
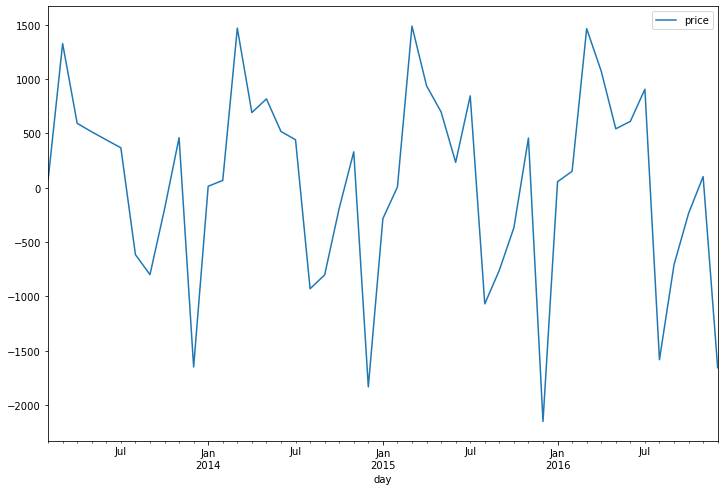
> 차분과 결측치를 제거한 데이터를 시각화한 모습이다.
> 다시 정상성을 만족하는지 확인해 보자.
|
1
2
3
|
adf = adfuller(diff_data, regression='c')
print('ADF Statistic : {}'.format(adf[0]))
print('p-value : {}'.format(adf[1]))
|
cs |
> 마찬가지로 가설을 제시함과 동시에 adfuller()를 통해서 검정을 진행한다.
귀무가설 : 해당 데이터가 정상성을 갖지 않는다.
대립가설 : 해당 데이터가 정상성을 갖는다.
|
1
2
|
ADF Statistic : -12.094547576926411
p-value : 2.0851606399612174e-22
|
cs |
> 진행한 결과는 유의확률(p-value)이 유의 수준(0.05) 보다 낮으므로 귀무가설 기각한다.
> 즉, 해당 데이터는 정상성을 갖는다고 할 수 있다.
OUTTRO.
여기서는 시계열 분해, 정상성에 대해서 다뤄보았다.
데이터 시각화를 통해서 시계열 분해요인인 추세, 계절성, 잔차에 대해서 확인하며 정상성에 위배되는 비정상 시계열임을 확인했다.
정상 시계열로 만들기 위해 차분을 진행하고 정상성 검정을 진행한 결과 만족한다는 결과를 마주할 수 있었다.
다음 글에서는 시계열분석에서 AR모형, MA모형, ARIMA모형에 대해서 정리하며 다뤄보고자 한다.
'내가 하는 데이터분석 > 내가 하는 통계분석' 카테고리의 다른 글
| [시계열 분석, Timeseries Analysis] - AR, MA, ARIMA with Python (0) | 2023.01.28 |
|---|---|
| [연관분석, Association Analysis] with Python (0) | 2023.01.18 |
| [군집분석, Clustering] - 비계층적 군집분석 with Python (4) | 2023.01.16 |
| [군집분석, Clustering] - 계층적 군집분석 with Python (0) | 2023.01.14 |
| [교차분석, ChiSquare Test] with Python (0) | 2023.01.12 |



