각 객체의 유사성을 측정해서 유사성이 높은 대상집단을 분류하는 군집분석을 정리해 보자.
그중에서 군집의 수를 미리 정하지 않는 방식으로 군집을 형성하는 계층적 군집분석에 대해서 정리해 보자.
이전엔 교차분석에 대해서 정리해보았다.
교차분석(ChiSquare Test)
각 범주에 따른 종속변수의 분포를 설명하거나, 두 변수가 서로 연관성이 있는지를 검정하는 교차분석 즉, 카이제곱 검정을 통해 정리해 보자. 이전에 T검정과 분산분석에서는 종속변수가 연속
py-moon.tistory.com
종속변수가 존재하지 않는 군집분석은 비지도 학습이다.
군집화의 단계
- 특성변수의 선정
- 유사성의 측정
- 군집의 도출
- 해석과 활용
계층적 군집분석을 수행하기 위해 USArrests데이터를 사용한다.
|
1
2
3
4
5
6
7
8
9
10
|
import pandas as pd
import numpy as np
from scipy.cluster.hierarchy import dendrogram, linkage, fcluster
from matplotlib import pyplot as plt
US = pd.read_csv('data/USArrests.csv')
US.columns = ['State', 'Murder', 'Assault', 'UrbanPop', 'Rape']
labelList = US.State.tolist()
US.head()
|
cs |
> 분석에 사용될 라이브러리와 데이터를 불러와준다.
> 8줄에서 군집화의 첫 번째 단계인 특성변수(도시 명, 살인 체포, 폭행 체포, 도시 인구 비율, 강간 체포)를 임의로 선정해 준다.
> 이를 통해서 범죄비율이 상대적으로 높은 군집과 낮은 군집을 형성해서 그 특징을 살펴보고자 한다.
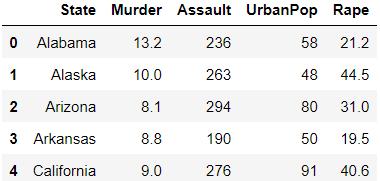
> 상위 5개의 데이터를 살펴본 결과 위와 같은 데이터를 확인할 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
single = linkage(US.iloc[:,1::], metric='euclidean', method='single')
plt.figure(figsize=(10, 7))
dendrogram(single,
orientation = 'top',
labels = labelList,
distance_sort = 'descending',
color_threshold = 25,
show_leaf_counts = True)
plt.axhline(y = 25, color = 'r', linewidth = 1)
plt.show()
|
cs |
> 군집화의 두 번째 단계인 유사성의 측정이다.
> 이번 계층적 군집분석에서는 유사성 측정으로 거리 계수 중 하나인 유클리드 거리를 사용한다.
> 그리고 계층적 군집화에서 사용되는 거리기반 알고리즘 중 최단연결법을 사용해보기로 한다.
> 최단 연결법 : 한 군집의 점과 다른 군집의 점 사이의 거리 가운데 가장 짧은 거리를 군집의 기준으로 이용한다.
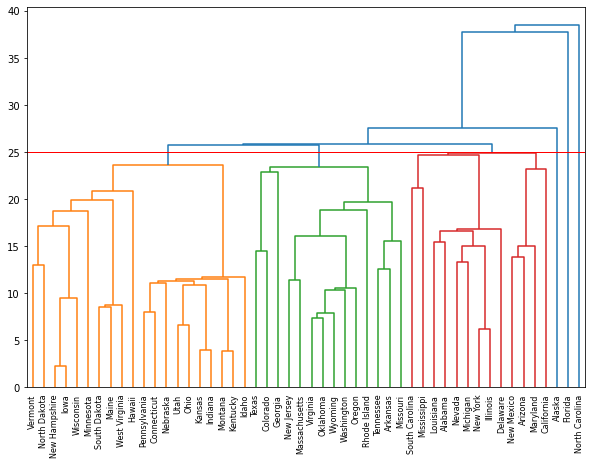
> 군집화의 세 번째 단계인 군집의 도출이다.
> 덴드로그램은 군집분석을 종료하는 기준으로 쓰인다.
> 임계값인 t를 25로 하고 군집화를 시켰을 때 약 6개의 군집이 형성되었다.
> 왼쪽의 3개는 객체가 모여 군집을 형성하고 있지만, 오른쪽 3개는 하나의 객체가 하나의 군집으로 형성되어 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
ward = linkage(US.iloc[:,1::], metric='euclidean', method='ward')
plt.figure(figsize=(10, 7))
dendrogram(ward,
orientation = 'top',
labels = labelList,
distance_sort = 'descending',
color_threshold = 250,
show_leaf_counts = True)
plt.axhline(y = 250, color = 'r', linewidth = 1)
plt.show()
|
cs |
> 이번엔 계층적 군집화에서 사용되는 오차제곱 알고리즘 중 와드연결법을 사용하고자 한다.
> 와드연결법 : 군집 내의 오차제곱합이 최소가 되도록 개체들을 묶어 나가는 방법이다.
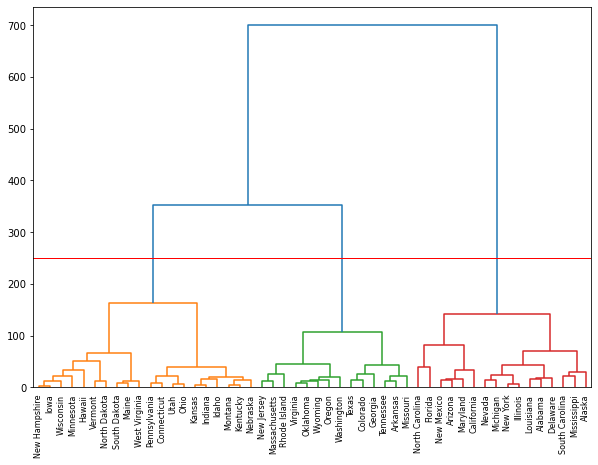
> 이번엔 임계값인 t를 250으로 놓았다.
> 결과를 보니 3개의 군집으로 형성이 되었고, 최단연결법을 사용했을 때보단 결과해석이 더 용이해 보인다.
> 모든 경우가 그렇진 않지만 와드연결법이 덴드로그램으로 결과를 해석하기 쉽다는 장점이 있다고 한다.
|
1
2
3
4
|
assignments = fcluster(ward, 250, 'distance')
US['cluster'] = assignments
US.groupby('cluster').mean()
|
cs |
> 결과에 대해서 수치로 확인해보고자 각 군집의 특성별 평균을 추출해 보았다.

> 추출한 결과를 해석하자면,
> 1번 군집에선 2번, 3번 군집보단 살인, 폭행, 강간이 많으므로 상대적으로 치안이 좋지 않은 도시로 보인다.
> 이러한 인사이트를 도출하는 과정이 군집화의 네 번째 단계인 해석과 활용에 해당한다.
OUTTRO.
일반적으로 지금까지의 분석은 대부분 종속변수가 존재하고 분류나 예측을 진행하는 지도학습에 해당했다.
하지만 비지도학습인 군집분석은 그 과정이 생소할 따름이다.
분석과제를 할 때 데이콘을 자주 활용하는 편인데 데이콘에서도 비지도학습은 자주 등장하지 않는 것 같다.
덴드로그램에서 최단연결법과 와드연결법의 결과가 차이가 있었음을 알 수 있다.
계산적을 단순한 최단연결법과 다르게 와드연결법은 오차를 계산하여 그 합을 최소화하는 디테일한 과정이 들어가서 그렇지 않나 하는 생각이 든다.
각각의 거리측정 방법의 목적에 따라 그 효과가 나타날 것이다.
최단연결법은 고립된 군집을 찾는데 중점을 둔 방법이라고 한다.
'내가 하는 데이터분석 > 내가 하는 통계분석' 카테고리의 다른 글
| [연관분석, Association Analysis] with Python (0) | 2023.01.18 |
|---|---|
| [군집분석, Clustering] - 비계층적 군집분석 with Python (4) | 2023.01.16 |
| [교차분석, ChiSquare Test] with Python (0) | 2023.01.12 |
| [다중 회귀분석, Multiple Regression] - 다중공선성 with Python (0) | 2023.01.10 |
| [선형 회귀분석, Linear Regression] with Python (0) | 2023.01.08 |



