하나 혹은 그 이상의 원인(독립변수)이 종속변수에 미치는 영향을 추적해서 식으로 표현하는 회귀분석을 복습해 보자.
이 전엔 이원배치 분산분석(Two-way ANOVA)에 대해서 정리해 보았다.
이원배치 분산분석(Two-way ANOVA)
두 개 이상의 다수 집단 간 평균은 비교하는 분산분석에서 이원배치 분산분석을 복습해 보자. 기본가정 정규성, 독립성을 만족한다 (아닐 시 Friedman test진행) 등분산성을 만족한다 (아닐 시 Welch`s
py-moon.tistory.com
회귀분석의 검토사항
- 모형이 데이터를 잘 적합하고 있는가?
- 회귀모형이 통계적으로 유의한가?
- 모형은 데이터를 얼마나 설명할 수 있는가?
- 모형 내의 회귀계수는 유의한가?
회귀분석은 kc_house_data를 활용해서 정리하고자 한다.
|
1
2
3
4
5
|
import pandas as pd
import numpy as np
house = pd.read_csv('data/kc_house_data.csv')
house = house[['price', 'sqft_living']]
|
cs |
> 분석에 필요한 데이터를 불러온다.
> 분석에 필요한 데이터인 독립변수(sqft_living)와 종속변수(price)를 house라는 변수로 불러온다.
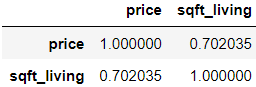
> 불러온 두 변수 간에 상관관계를 알아보기 위해 상관계수를 확인해 본다.
> 약 0.7의 강한 양의 상관관계를 가지는 것으로 확인된다. 따라서 두 변수간 선형성을 가정한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
from statsmodels.formula.api import ols
import matplotlib.pyplot as plt
y = house['price'] # 종속변수
X = house['sqft_living'] # 독립변수
lr = ols('price ~ sqft_living', data=house).fit()
y_pred = lr.predict(X)
plt.scatter(X, y) # 원본 데이터에 대한 산포도
plt.plot(X, y_pred, color='red') # 산출한 예측치에 대한 회귀직선
plt.xlabel('sqft_living', fontsize=10)
plt.ylabel('price', fontsize=10)
plt.title('Linear Regression Result')
plt.show()
|
cs |
> 첫 번째 검토사항인 '모형이 데이터를 잘 적합하고 있는지'를 알아보기 위해 원본 데이터에 대한 산포도와 산출한 예측치에 대한 회귀직선을 시각화해 보았다.
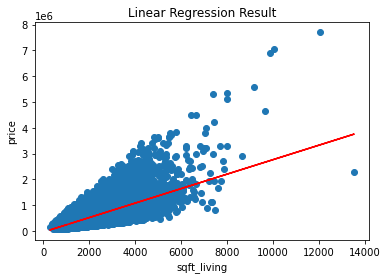
> 그 결과 직관적으로도 빨간 직선이 원본데이터를 잘 설명하고 있다고 보기엔 어렵다는 것을 알 수 있다.
> 그리고, 산포도(오차)가 (0,0)을 기준으로 점점 분산이 커지는 형태임이 확인되며 특정 형태를 띠고 있음을 알 수 있다.
> 즉, 잔차가 특정 패턴을 이루지 않아야 한다는 1번 검토사항에 그렇지 않다는 결과를 보여주고 있다.
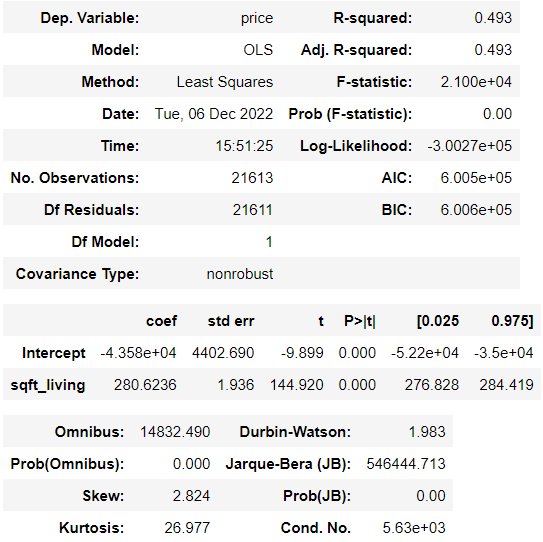
> 나머지 검토사항에 대해 검증하기 위해 summary() 함수를 사용했다.

> 2번 검토사항인 회귀모형이 통계적으로 유의한가를 알아보기 위해 F통계량의 유의확률을 알아본다.
귀무가설 : 회귀모형은 통계적으로 유의하지 않다.
대립가설 : 회귀모형은 통계적으로 유의하다.
> 위 결과에서 F통계량의 유의확률(Prob F-statistic)이 유의 수준(0.05) 보다 작으므로 귀무가설을 기각하고 대립가설을 채택한다.
> 즉, 이번 회귀분석에 사용된 회귀모형은 통계적으로 유의하다는 결과이다.
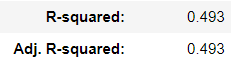
> 3번 검토사항인 모형은 데이터를 얼마나 설명할 수 있는가를 알아보기 위해 결정계수를 확인한다.
> 위 시각화된 자료에서도 확인했듯이 직관으론 회귀직선인 데이터를 잘~ 설명한다고 보기엔 어려움이 있어 보였다.
> 이를 통계적으로 확인해 본 결과 결정계수가 0.493으로 이 모형이 전체 데이터의 49.3%를 설명하고 있다고 볼 수 있다.
> 49.3%를 설명한다는 것이 상황에 따라 그 정도를 판단할 수 있다.
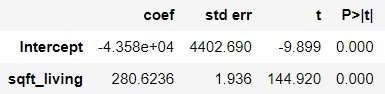
> 4번 검토사항인 모형 내의 회귀계수는 유의한가를 검증하기 위해 T통계량의 유의확률을 확인한다.
귀무가설 : 모형 내의 회귀계수는 통계적으로 유의하지 않다.
대립가설 : 모형 내의 회귀계수는 통계적으로 유의하다.
> 우리는 독립변수인 sqft_living 변수에 대한 회귀계수를 보아야 한다.
> 유의확률(P>|t|)이 0으로 유의 수준(0.05) 보다 작으므로 통계적으로 유의한 변수라고 할 수 있다.
> 즉, 분석에 사용된 모형 내의 회귀계수는 통계적으로 유의하다는 결과이다.
OUTTRO.
선형 회귀분석은 분석과제를 수행할 때도, 통계분석을 할 때도 많이 쓰이는 방법 중 하나이다.
하지만 많이 쓰이는 것만큼 잘 알고 쓰는지에 대한 의문이 든다.
나에겐 검증의 목적으로 사용되는 회귀분석은 언제 쓰는 것인가, 어떻게 쓰는 것인가를 되뇌게 하는 요소이다.
그럼에도 나는 회귀분석이 선형성이 만족된 독립변수와 종속변수 간의 영향을 통계적인 수치로 증명할 수도, 회귀식을 통해 예측에 활용할 수도 있는 분석 방법 중 하나라고 정리가 된다.
'내가 하는 데이터분석 > 내가 하는 통계분석' 카테고리의 다른 글
| [교차분석, ChiSquare Test] with Python (0) | 2023.01.12 |
|---|---|
| [다중 회귀분석, Multiple Regression] - 다중공선성 with Python (0) | 2023.01.10 |
| [이원배치 분산분석, Two-way ANOVA] with Python (0) | 2023.01.06 |
| [일원배치 분산분석, One-way ANOVA] with Python (0) | 2023.01.02 |
| [독립표본 T-검정, Independent Sample T-Test] with Python (0) | 2022.12.29 |



