두 집간 간의 평균 차이를 검정하는 T검정에서 독립표본 T-검정을 복습해보자.
이 전엔 대응표본 T-검정에 대해서 정리하고 복습해 보았다.
대응표본 T-검정
두 집간 간의 평균 차이를 검정하는 T검정에서 대응표본 T-검정을 복습해보자. 기본가정 정규성 만족 (아닐 시 윌콕슨의 부호 순위 검정) 종속변수는 연속형, 독립변수 1개 범주형 짝(개수) 만족 .
py-moon.tistory.com
기본가정
- 정규성 만족 (아닐 시 윌콕슨이 부호 순위 검정, 맨휘트니 검정)
- 등분산성 만족 (아닐 시 Welch`s t-test)
- 종속변수는 연속형, 독립변수는 1개 범주형
독립표본 T검정에 대한 정리는 고양이에 대한 데이터를 통해 진행해 보겠다.
|
1
2
3
4
|
import pandas as pd
cats = pd.read_csv('data/cats.csv')
cats.head()
|
cs |
> 가설검정에 사용될 고양이 데이터를 불러온다.
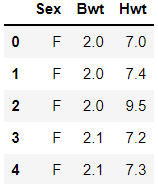
> cats.head를 통해 상위 5개 데이터와 변수들을 확인한다.
|
1
2
3
4
5
6
7
8
|
import scipy.stats as stats
from scipy.stats import shapiro
male = cats[cats['Sex']=='M']['Bwt']
female = cats[cats['Sex']=='F']['Bwt']
print("male 변수에 대한 정규성 검정 결과 :", shapiro(male))
print("female 변수에 대한 정규성 검정 결과 :", shapiro(female))
|
cs |
> 독립표본 T검정의 기본 가정 중 정규성 만족을 확인해보기 위한 코드이다.
> 4,5줄에선 수컷 고양이의 몸무게 데이터만을 담은 male 변수와, 암컷 고양이의 몸무게 데이터만을 담은 female 변수로 구성해서 검정을 진행하고자 한다.
> 일표본 T검정이나 대응표본 T검정에는 없었던 등분산 검정을 하는 방법을 주로 다루어 보기위해 정규성에 대한 조건은 충족한다는 가정 하에 진행하고자 한다.
> 위 코드를 실행시키면 해당 결과가 나오므로 정규성에 대한 부분을 확인 할 순 있다.
|
1
2
3
|
import scipy.stats as stats
stats.levene(female, male)
|
cs |
> 위에서 만든 두 변수(male, female)에 대해서 독립표본 T검정의 기본 가정인 등분산을 이루는지에 대해 알아보고자 한다.
귀무가설 : 두 집단의 분산이 등분산을 이룬다.
대립가설 : 두 집단의 분산이 서로 다른 이분산을 이룬다.
|
1
|
LeveneResult(statistic=19.43101190877999, pvalue=2.0435285255189404e-05)
|
cs |
> 알아본 결과 유의확률(pvalue)이 유의수준(0.05)보다 작으므로 귀무가설을 기각하고 대립가설을 채택한다.
> 즉, male과 female의 분산이 서로 다르다는 것이다.
|
1
2
3
|
import scipy.stats as stats
stats.ttest_ind(female, male, equal_var=False)
|
cs |
> 두 집단에 대해서 평균차이를 검정하기 위해 stats.ttest_ind()를 활용하였다.
> 위 등분산 검정에서 이분산이라는 결과가 나왔으므로 stats.ttest_ind()에서 equal_var을 False로 맞춰준 후 코드를 실행시킨다.
귀무가설 : 수컷과 암컷 고양이의 몸무게 차이는 없다.
대립가설 : 수컷과 암컷 고양이의 몸무게 차이가 있다.
|
1
|
Ttest_indResult(statistic=-8.70948849909559, pvalue=8.831034455859356e-15)
|
cs |
> 실행한 결과 유의확률(pvalue)이 유의수준(0.05)보다 작으므로 귀무가설을 기각하고 대립가설을 채택한다.
> 즉, 수컷과 암컷 고양이의 몸무게 사이엔 차이가 있다는 것이다.
> T검정의 결과에 대해서 시각화를 해보았지만 그래프만을 보았을 땐 그 차이가 명확하게 보이지 않는다.
> 데이터를 통해 각 집단의 평균을 출력해보았다.
|
1
2
3
4
5
|
print("수컷 고양이의 평균 몸무게 : {:.1f}kg" .format(male.mean()))
print("암컷 고양이의 평균 몸무게 : {:.1f}kg" .format(female.mean()))
수컷 고양이의 평균 몸무게 : 2.9
암컷 고양이의 평균 몸무게 : 2.4
|
cs |
> T검정의 결과에 대해서 데이터로 확인해본 결과 평균에 명확한 차이를 확인할 수 있다.
여러 데이터를 가지고 분석 과제를 진행하다보면 도대체 통계분석은 언제 진행하는지, 언제하면 좋을지에 대한 의문이 든다.
막상 통계분석을 공부하고 정리하다보면 고개를 끄덕이며 이해하지만 실무에 적용하는 것이 쉽지 않은 것 같다는 생각이 든다.
아직 나의 분석이 미숙한 탓일지, 지금껏 해온 분석과제에선 불필요한 것들이었는지는 모르지만 전자의 이유일 것이라는 추측이 가능하다.
앞으로의 분석과제를 임할 때 불필요할지라도 해보려는 노력은 해볼 가치가 있을 것 같다.
'내가 하는 데이터분석 > 내가 하는 통계분석' 카테고리의 다른 글
| [선형 회귀분석, Linear Regression] with Python (0) | 2023.01.08 |
|---|---|
| [이원배치 분산분석, Two-way ANOVA] with Python (0) | 2023.01.06 |
| [일원배치 분산분석, One-way ANOVA] with Python (0) | 2023.01.02 |
| [대응표본 T-검정, Paired Samles T-Test] with Python (2) | 2022.12.27 |
| [일표본 T-검정, One Sample T-Test] with Python (0) | 2022.12.25 |



