진행 기간 : 20220801 ~ 20221019
이 전글에선 공모전에서 진행한 모델링에 관한 내용을 다루었다.
공연예술통합전산망(KOPIS) 빅데이터 분석 공모전 4편 모델링
진행 기간 : 20220801 ~ 20221019 이 전글에선 공모전을 진행하며 전처리에 대한 부분을 정리하며 다뤄보았다. 공연예술통합전산망(KOPIS) 빅데이터 분석 공모전 3편 전처리 진행 기간 : 20220801 ~ 20221019
py-moon.tistory.com
모델링에서 총 7가지의 모델을 가지고 cross_val_score을 사용해서 모델을 학습시키고 성능을 출력한 다음, 비교해 본 결과로 로지스틱 회귀모델이 가장 안정적이고도 높은 성능을 내주어서 최종 모델로 선정하게 되었다.
이번 글에서 정리 할 내용은 분석과정에서 알 수 있었던 인사이트에 대해 시각화 라이브러리(Seaborn, Matplotlib)를 통해서 보기 쉽게 차트로 구현해 보았다.
이전 글들에서도 중간중간 필요한 차트가 나오긴 하지만 이번에 공유할 것은
2019년 하반기부터 2022상반기까지의 데이터 중 연극이라는 장르만으로 추린 데이터로, 최종 모델링까지 마치면서 데이터를 통해 해석할 수 있었던 부분이다.
각 분야별로 2개의 차트가 존재하는데
첫 번째는 비율을 보여주는 것이고, 두 번째는 데이터 개수에 기반한 시각화 자료이다.
|
1
2
3
4
5
6
7
8
9
10
|
import pandas as pd
import seaborn as sns
import scipy.stats as stats
from scipy.stats import *
from matplotlib import pyplot as plt
import numpy as np
import warnings
warnings.filterwarnings('ignore')
original = pd.read_excel("c:/kopis/원작 정리/최종 원작 정리(확정).xlsx")
|
cs |
> 시각화에 필요한 모듈과 라이브러리을 불러오고, 시각화에 사용될 파일을 불러온다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
ratio = [original.loc[original['원작 형태']=="도서"]['원작'].count(),
original.loc[original['원작 형태']=="웹툰"]['원작'].count(),
original.loc[original['원작 형태']=="영화"]['원작'].count()]
labels = ['도서', '웹툰','영화']
explode = [0, 0.10, 0.10]
colors = ['#FFF8DC', '#DCDCDC','#F08080']
plt.rcParams['figure.figsize'] = (5, 5)
plt.rcParams['font.size'] = 15
plt.rcParams['font.family'] = 'Malgun Gothic'
plt.title('원작의 형태 별 각색 연극 비율')
plt.pie(ratio, labels=labels,autopct='%.1f%%',explode=explode,colors=colors,shadow=True)
plt.show()
|
cs |
> 원작의 형태별 각색 연극 비율에 대해서 인사이트를 도출하기 위해 파이차트를 통해서 시각화해보았다.

> 도서를 각색한 연극의 비율이 약 92.9%로 대다수를 차지하는 것을 확인할 수 있었다.
> 이를 통해 19년도 하반기부터 22년도 상반기까지의 각색된 연극 중에는 도서를 각색한 연극의 비율이 압도적인 것을 알 수 있었다.
|
1
2
3
4
5
6
7
8
9
10
|
plt.rcParams["figure.figsize"]=(5,5)
sns.set_style('whitegrid')
sns.set(font="Malgun Gothic",
rc={"axes.unicode_minus":False},
style='darkgrid')
g=sns.barplot(x='원작 형태', y='최종 일일 관객수', palette='Set3',data=original, ci=None)
g.set_title('원작 형태에 따른 평균 연극관객수',fontsize = 15, pad=30)
g.set_xticklabels(['도서','영화','웹툰'], fontsize = 15)
plt.xlabel('', fontsize = 15)
plt.ylabel('평균 관객수(명)', fontsize = 15)
|
cs |
> 원작 형태에 따른 평균 연극 관객 수에 대해 비율이 아닌 값에 대한 시각화를 통해 해석해 보고자 한다.
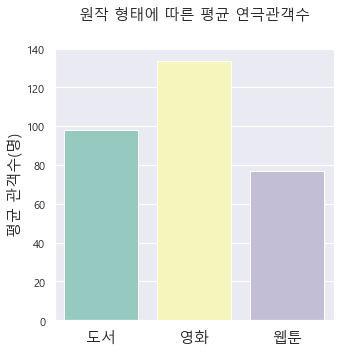
> 원작 형태에 따른 일일 평균 연극 관객수를 나타내는 그래프 결과를 살펴보면 영화를 각색한 연극이 일일 평균 관객 수가 가장 많았고 다음으로 도서, 웹툰 순이라는 것을 확인할 수 있었다.
> 따라서, 연극의 횟수에 따른 비율은 도서를 각색한 연극이 전체의 대부분을 차지하였으나 비율이 약 4.6%에 이르는 영화를 각색한 연극의 관객 수는 세 항목 중 가장 많은 연극 관객 수를 기록했다는 사실을 확인할 수 있었다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
ratio = [original.loc[original['원작 세부장르']=="동화"]['원작'].count(),
original.loc[original['원작 세부장르']=="소설"]['원작'].count(),
original.loc[original['원작 세부장르']=="희곡"]['원작'].count(),
original.loc[original['원작 세부장르']=="기타"]['원작'].count()]
labels = ['동화', '소설','희곡','기타']
explode = [0.1, 0.05, 0.05, 0.1]
colors = ['#FFF8DC','#ff9999', '#ffc000', '#8fd9b6', '#d395d0']
plt.rcParams['figure.figsize'] = (5, 5)
plt.rcParams['font.size'] = 15
plt.rcParams['font.family'] = 'Malgun Gothic'
plt.title('도서 세부장르 별 각색 연극 비율', size=15)
plt.pie(ratio, labels=labels,autopct='%.1f%%',explode=explode,colors=colors,shadow=True, textprops={'size': 15})
plt.show()
|
cs |
> 다음은 도서 세부장르 별 각색 연극 비율에 대해서 시각화를 해보았다.
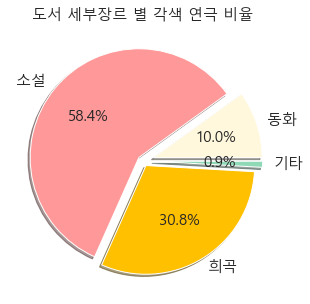
> 원작의 형태 중 가장 많은 부분을 차지했던 도서를 가지고 세부 장르 별 각색된 연극의 비율을 살펴보면 소설이 58.4%로 가장 많은 부분을 차지했고, 다음으로 희곡, 동화 순으로 비율을 나타내고 있다.
> 이를 통해 도서 중에서 희곡이나 동화보다는 소설을 가지고 각색한 연극의 비율이 다수를 차지하고 있다는 사실을 확인할 수 있었다.
|
1
2
3
4
5
6
7
8
9
|
plt.rcParams["figure.figsize"]=(5,5)
sns.set_style('whitegrid')
sns.set(font="Malgun Gothic",
rc={"axes.unicode_minus":False},
style='darkgrid')
g=sns.barplot(x='원작 세부장르', y='최종 일일 관객수', palette='Set3',data=original.loc[original['원작 형태']=="도서"], ci=None)
g.set_title('도서 세부장르에 따른 평균 연극관객수',fontsize = 15, pad=30)
plt.xlabel('', fontsize = 15)
plt.ylabel('평균 관객수(명)', fontsize = 15)
|
cs |
> 이번에도 도서 세부 장르에 따른 평균 연극 관객 수에 대한 시각화를 해보았다.

> 도서 세부 장르에 따른 일일 평균 연극 관객 수를 살펴보면, 희곡과 동화를 가지고 각색한 연극의 일일 평균 관객 수가 가장 많았고 다음으로 소설이 있었다.
> 따라서, 연극의 횟수에 따른 비율은 도서 중에서 소설을 각색한 연극이 전체의 다수를 차지하였으나 희곡이나 동화를 각색한 연극의 일일 평균 관객 수가 많은 관객 수를 기록했다는 사실을 확인할 수 있었다.
|
1
2
3
4
5
6
7
8
9
10
11
|
ratio = [original.loc[original['국내/외국']==0]["원작"].count(),
original.loc[original['국내/외국']==1]["원작"].count()]
labels = ['국내', '외국']
explode = [0.03, 0.03]
colors = ['#FFF8DC', '#DCDCDC']
plt.rcParams['figure.figsize'] = (5, 5)
plt.rcParams['font.size'] = 15
plt.rcParams['font.family'] = 'Malgun Gothic'
plt.title('국내/외국 작품 별 각색공연 비율')
plt.pie(ratio, labels=labels,autopct='%.1f%%',explode=explode,colors=colors,shadow=True)
plt.show()
|
cs |
> 마지막으로 국내/외국 작품 별 각색 공연 비율에 대한 시각 자료를 보고 해석해보고자 한다.
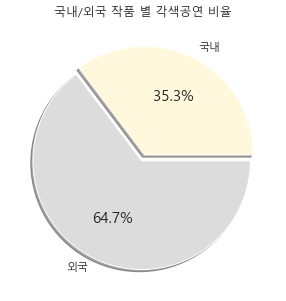
> 원작의 형태 중 가장 많은 부분을 차지했던 도서에 대해서 국내작품과 외국 작품으로 나누어 각색 공연의 비율을 나타낸 결과를 보면 외국 도서를 가지고 각색한 연극이 국내 도서를 가지고 각색한 연극보다 많았다는 것이다.
|
1
2
3
4
5
6
7
8
9
10
|
plt.rcParams["figure.figsize"]=(5,5)
sns.set_style('whitegrid')
sns.set(font="Malgun Gothic",
rc={"axes.unicode_minus":False},
style='darkgrid')
g=sns.barplot(x='국내/외국', y='최종 일일 관객수', palette='Set3',data=original.loc[original['원작 형태']=="도서"], ci=None)
g.set_title('국내/외국 도서 별 평균 연극관객수',fontsize = 15, pad=30)
g.set_xticklabels(['국내','외국'], fontsize = 15)
plt.xlabel(' ', fontsize = 15)
plt.ylabel('평균 관객수(명)', fontsize = 15)
|
cs |
> 국내/외국 도서 별 평균 연극 관객 수에 대한 시각 자료를 통해 인사이트를 도출하고자 한다.
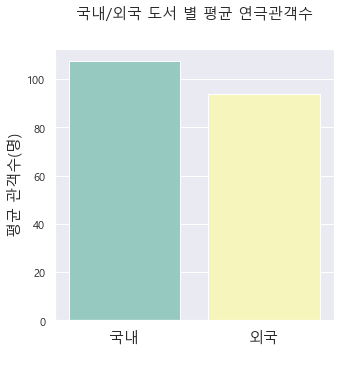
> 일일 평균 관객 수를 따지고 보면 국내 도서를 가지고 각색한 연극 관객 수가 외국 도서보다 많았다는 결과를 볼 수 있었다.
> 시각화한 자료들을 보며 공통점은 연극의 횟수에 따른 비율이 해당 연극에 대한 일일 평균 연극 관객 수와 비례하지 않다는 점과 연극의 횟수가 많은 작품이라고 해서 그 작품이 관객 수를 책임지지는 못한다는 것이었다.
OUTTRO.
공모전을 진행하면서 협업하며 데이터를 다뤄볼 수 있는 기회였고, 혼자 할 수 있는 수준보다 더 나은 질의 분석을 할 수 있어서 의미 있는 시간이라고 생각한다.
하지만 공모전을 진행하며 우리가 느꼈던 한계점에 대해서 말해보려 한다.
첫 번째는 관객 수라는 파생변수는 임의로 산출해서 구한 변수이므로 정확한 지표라고는 할 수 없다는 부분이었다. 데이터 제공처에서 관객 수에 대한 데이터가 있었더라면 좋았겠다는 생각을 했고, 파생변수라 할지라도 다른 방법으로 관객 수를 구할 방법은 없었을까 하는 생각이 들었다.
두 번째는 모델에 사용될 원작 관련 데이터를 구하기 어려웠다는 점이다. 우리 주제가 원작이라는 키워드에 중점을 두었기 때문에 원작에 대한 데이터가 필수적이었다. 하지만 제공되지 않는 데이터였던 이유로 충분한 양을 마련할 수도 없었고, 일일이 찾아야 하는 과정이 시간을 많이 소모할 수밖에 없었던 것 같다.
세 번째는 예측 모델을 만들 때 흥행성공 기준을 엄격하게 하기 위해 흥행성공 비율을 줄여 자체적으로 데이터 불균형을 만들어 모델을 생성했었다. 물론 데이터 불균형 문제를 해결하는 언더샘플링, 오버샘플링, SMOTE를 활용해 보았지만 성능이 좋지 못했기 때문에 반영할 수 없었다. 결과적으로 성능이 좋지 못했던 이유 중 데이터 불균형에서 오는 문제도 분명 있었을 것이라고 생각한다.
'내가 하는 데이터분석 > 내가 했던 공모전' 카테고리의 다른 글
| 공연예술통합전산망(KOPIS) 빅데이터 분석 공모전 4편 모델링 (0) | 2022.12.21 |
|---|---|
| 공연예술통합전산망(KOPIS) 빅데이터 분석 공모전 3편 전처리 (0) | 2022.12.20 |
| 공연예술통합전산망(KOPIS) 빅데이터 분석 공모전 2편 가설2 (0) | 2022.12.18 |
| 공연예술통합전산망(KOPIS) 빅데이터 분석 공모전 1편 가설1 (0) | 2022.12.16 |



