진행 기간 : 20220801 ~ 20221019
이 전에는 가설1에 대해서 다뤄보았다.
공연예술통합전산망(KOPIS) 빅데이터 분석 공모전 1편 가설1
20220801 ~ 20221019 우연한 계기로 처음보는 2명의 팀원들과 같은 뜻을 가지고 공모전에 참여하게 되었다. 주제는 공연소비, 유통 측면에서 시장 문제점을 해결 및 발전시킬 수 있는 범주 내 자유주
py-moon.tistory.com
1편에서는 가설1에 해당하는 각색 여부에 따른 연극 관객 수의 평균 차이를 검정하는 것이었다.
결과는 그 평균의 차이가 유의하지 않다는 것이었다.
이번에 정리할 내용은
가설2에 해당하는 원작의 흥행 정도와 해당 원작을 각색한 연극의 관객 수 간에 상관관계 검정이다.
귀무가설 : 원작의 흥행정도와 해당 원작을 각색한 연극의 관객 수 간에 상관관계가 존재하지 않는다.
대립가설 : 원작의 흥행정도와 해당 원작을 각색한 연극의 관객 수 간에 상관관계가 존재한다.
이번 가설을 검정하기 위해선 원작에 대한 정보가 필수적이고 데이터가 필요했다.
우리는 그에 대한 정보를 도서관 정보나루 사이트에서 가져왔고, 제공된 데이터에선 공연명이 제공되지 않았기 때문에 각각 공연코드로 검색을 해보기도 했고, 공연 정보로 해당공연을 추려내는 작업을 수행해야만 했다.
그렇게 추려낸 공연명을 가지고 원작을 찾았지만 도서를 원작으로 한 연극이 더 많았기 때문에 우리는 원작 중에서도 도서를 원작으로 한 연극에 초점을 두기로 했다.
도서의 흥행 요소로는 판매 건수가 있겠지만 도서 판매처에서 가용할 만한 데이터가 마땅치 않아 차선책으로 도서관 정보나루 사이트에 기록되어 있는 도서 대출 수를 가져왔다.
|
1
2
3
4
5
6
7
8
|
import pandas as pd
import seaborn as sns
import scipy.stats as stats
from scipy.stats import *
from matplotlib import pyplot as plt
import numpy as np
import warnings
warnings.filterwarnings('ignore')
|
cs |
> 가설2 검정에 앞서 필요한 모듈과 라이브러리를 미리 불러온다.
|
1
|
original = pd.read_excel("C:/Users/82102/Desktop/kopis 공모전/원작 정리.xlsx")
|
cs |
> 앞에서 설명한 원작에 대한 정보가 담긴 데이터를 수집한 파일을 original이라는 변수에 할당해 준다.
|
1
|
original_book = original.loc[original["원작 형태"]=="도서"]
|
cs |
> original에서 원작의 형태가 도서인 것만 추려서 original_book에 따로 만들어준다.
|
1
|
print("상관분석 : ", stats.pearsonr(original_book["최종 관객수"], original_book["대출수"]))
|
cs |
> original_book에 있는 최종 관객 수와 대출 수 사이에 상관관계를 파악하기 위해 피어슨 상관분석을 수행했다.
|
1
|
상관분석 : (-0.010236851861443356, 0.8802687290611825)
|
cs |
> 그 결과, 상관계수는 약 -0.01로 상관관계가 없다는 것과
> 유의확률은 약 0.88로 유의미한 결과가 아니라는 것이다.
|
1
2
3
4
5
6
7
8
9
10
|
target = original_book["최종 관객수"]
x_data = original_book["대출수"]
import statsmodels.api as sm
x_data1 = sm.add_constant(x_data, has_constant = "add")
multi_model = sm.OLS(target, x_data1)
fitted_multi_model = multi_model.fit()
fitted_multi_model.summary()
|
cs |
> 추가적으로 화귀분석을 통해서 둘 사이의 인과관계를 알아보고자 했다.
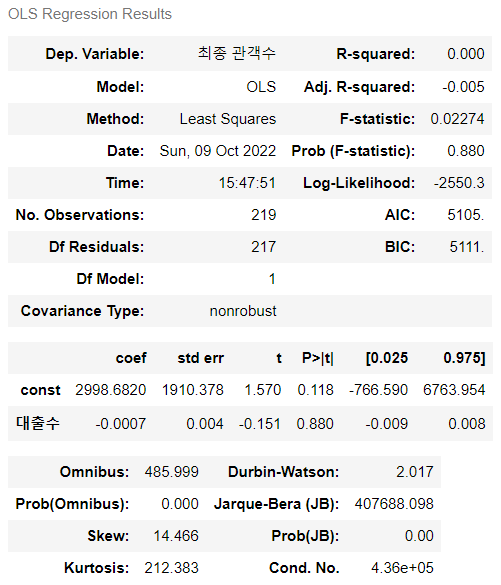
> 하지만, 유의확률이 0.88로 회귀모형 자체가 유의미하지 않다는 결과를 안겨다 주었다.
> 결론적으로 대출 수가 최종 관객 수에 미치는 영향은 없다는 인사이트이다.
사실, 이 결과는 직관으로 보면 인정하기 어려웠다.
대출 건수가 많은 도서를 원작으로 한 연극의 관객수가 당연히 많을 것 아닌가?????
통계적인 관점으로 보았을 때는 그렇지 않다는 게 팀원의 사기를 내팽개치는 사실이었다.
우리는 여기서 최종 관객 수를 공연기간으로 나누어 최종 일일 관객 수라는 변수를 생성했고, 위 과정처럼 상관분석과 회귀분석을 진행하였다.
|
1
|
print("상관분석 : ", stats.pearsonr(original_book["최종 일일 관객수"], original_book["대출수"]))
|
cs |
> 최종 일일 관객 수와 대출 수의 상관관계를 알아보기 위한 과정이고 마찬가지로 피어슨 상관분석을 활용했다.
|
1
|
상관분석 : (0.012721562195480679, 0.851510005859157)
|
cs |
> 결과는 상관계수가 약 0.01로 상관관계없음.
> 유의확률이 0.85로 결과가 유의하지 않음....이다.
|
1
2
3
4
5
6
7
8
9
10
|
target = original_book["최종 일일 관객수"]
x_data = original_book["대출수"]
import statsmodels.api as sm
x_data1 = sm.add_constant(x_data, has_constant = "add")
multi_model = sm.OLS(target, x_data1)
fitted_multi_model = multi_model.fit()
fitted_multi_model.summary()
|
cs |
> 마찬가지로 회귀분석도 진행해 보았다.
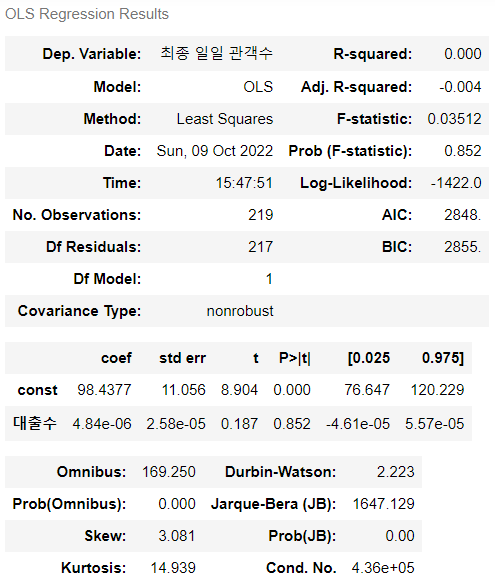
> 그 결과는 최종 관객 수로 검정을 진행했을 때와 비슷하게 회귀계수의 유의확률이 약 0.85로 회귀모형이 유의하지 않다는 것이었다.
> 분석을 기획했을 때 참고했었던 논문도 있었고, 어느 정도의 결과를 속단하며 진행했었지만 그 결과가 생각했었던 방향과 너무 다르게 흘러가는 것이 이후의 분석에 많은 영향을 끼칠까 두려웠다.
> 나뿐만 아니라 팀원들 또한 같은 생각으로 사기가 많이 저하된 분위기 속에서 분석을 멈출 수는 없는 것이 현실이었다. 바로 다음 단계가 모델링 단계인데 이대로면 기획했었던 회귀예측은 진행할 수 없는 상황이었다.
> 하지만 회의하고 의논하며 차선책을 찾은 덕분에 계속해서 분석을 이어갈 수 있었다.
'내가 하는 데이터분석 > 내가 했던 공모전' 카테고리의 다른 글
| 공연예술통합전산망(KOPIS) 빅데이터 분석 공모전 5편 시각화 (0) | 2022.12.23 |
|---|---|
| 공연예술통합전산망(KOPIS) 빅데이터 분석 공모전 4편 모델링 (0) | 2022.12.21 |
| 공연예술통합전산망(KOPIS) 빅데이터 분석 공모전 3편 전처리 (0) | 2022.12.20 |
| 공연예술통합전산망(KOPIS) 빅데이터 분석 공모전 1편 가설1 (0) | 2022.12.16 |



