진행 기간 : 20220801 ~ 20221019
이 전글에서는 가설2에 대해서 다뤄보면서 정리해 보았다.
공연예술통합전산망(KOPIS) 빅데이터 분석 공모전 2편 가설2
진행 기간 : 20220801 ~ 20221019 이 전에는 가설1에 대해서 다뤄보았다. 공연예술통합전산망(KOPIS) 빅데이터 분석 공모전 1편 가설1 20220801 ~ 20221019 우연한 계기로 처음보는 2명의 팀원들과 같은 뜻을
py-moon.tistory.com
앞선 글에서 두 가지의 가설을 검정하였다.
첫 번째 가설 : 각색 여부에 따른 연극 관객 수의 평균 차이가 존재할까?
결과는 그 평균의 차이가 유의하지 않다는 것.
두 번째 가설 : 원작의 흥행 정도와 해당 원작을 각색한 연극의 관객 수 간의 상관관계가 존재할까?
결과는 상관관계를 입증할 수 없다는 것이었다.
이러한 결과를 가지고는 회귀모델을 만들 수는 없었다.
팀원들과 회의한 결과 전제조건에 비교적 자유로운 분류모델을 구축해 보기로 했다.
흥행의 정도를 임의로 기준을 삼아 흥행 성공과 흥행 실패로 분류해주는 모델을 구축하기로 한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
%matplotlib inline
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import GradientBoostingClassifier
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import *
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
from statsmodels.stats.outliers_influence import variance_inflation_factor
import statsmodels.api as sm
import warnings
warnings.filterwarnings('ignore')
|
cs |
> 모델링에 필요한 모듈과 라이브러리를 미리 불러와준다.
|
1
2
|
df = pd.read_excel('c:/kopis/원작 정리/최종 원작 정리(확정).xlsx')
df = df[df["원작 형태"]=="도서"]
|
cs |
> 필요한 컬럼만을 남긴 데이터셋과 원작에 대한 정보가 들어간 데이터셋을 가진 파일을 불러오고
> 원작의 형태가 도서인 것만을 추려서 df라는 이름으로 할당한다.
|
1
|
df[['최종 일일 관객수']].describe()
|
cs |
> 흥행의 기준을 선정하기 위해 종속변수인 최종 일일 관객 수의 기초통계량을 확인한다.

> 기초통계량을 확인해보니 위처럼 나왔고, 흥행에 성공한 작품을 중점으로 예측하기 위해서 기준을 엄격하게 두어 상위 25% 수치를 따르기로 한다.
|
1
2
3
4
5
6
|
def func(x) :
if x > 142.451613 :
return 1
else :
return 0
df["흥행 여부"] = df["최종 일일 관객수"].apply(lambda x : func(x))
|
cs |
> 상위 25% 이상의 관객 수를 기록했다면 흥행 성공으로 1을, 이하라면 흥행 실패로 0을 return해주는 알고리즘으로 함수를 만들어 적용할 수 있게 코딩했다.
|
1
|
df['흥행 여부'].value_counts()
|
cs |
> 생성된 흥행 여부 컬럼의 value_counts()를 찍어보니
|
1
2
|
0 164
1 55
|
cs |
> 흥행에 성공했다고 보는 연극 작품은 55개, 흥행에 실패했다고 볼 수 있는 연극 작품은 164개로 분류된 걸 확인할 수 있다.
|
1
2
3
4
|
plt.rcParams['axes.unicode_minus'] = False
plt.rc('font', family='Malgun Gothic')
df[["대출수"]].hist(bins=20, figsize=(10,5))
|
cs |
> 독립변수로 쓸 대출 수 칼럼에 대해서 히스토그램을 확인해 보았다.
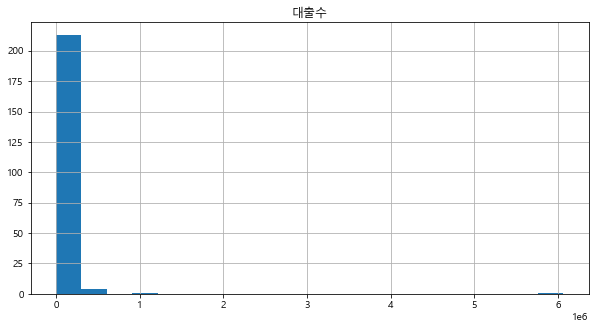
> 분포를 확인해보면 그래프가 심하게 좌측으로 기울어진 형태를 띠고 있다.
> 이를 스케일링하기 위해 우리는 로그 변환을 사용하기로 한다.
|
1
2
|
df[["대출수"]] = np.log1p(df[["대출수"]])
df[['대출수']].hist(bins=20, figsize=(10,5))
|
cs |
> 여기서 np.log1p()를 사용한 이유는 [내가 하는 전처리]에서 정리를 해놓았다.
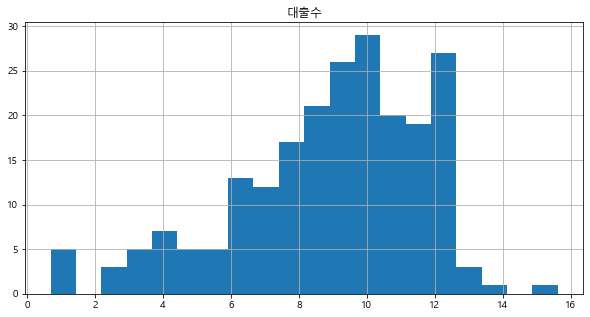
> 그래프 형태가 로그변환 전보다는 정규분포에 가까워짐을 확인할 수 있다.
|
1
2
3
4
|
logit = sm.Logit(df['흥행 여부'],df['대출수']) #로지스틱 회귀분석 시행
result = logit.fit()
result.summary2()
|
cs |
> 독립변수인 대출 수와 종속변수인 흥행 여부의 인과관계를 파악한 결과
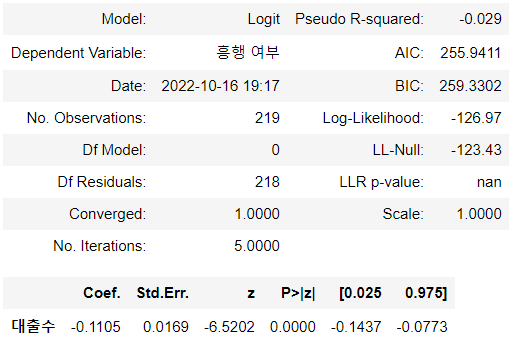
> 유의수준 0.05 기준으로 유의확률이 0.0000으로 유의수준보다 작았기에 대출 수가 흥행 여부에 미치는 영향력이 있음을 알 수 있다고 해석할 수 있다.
|
1
2
3
4
|
df['도서 연도'] = df['도서 연도'].map( {'현대': 0, '근대': 1, '고전': 2} ).astype(int)
df['국내/외국'] = df['국내/외국'].map( {'외국': 0, '국내': 1} ).astype(int)
dummies = pd.get_dummies(df["원작 세부장르"])
df = pd.concat([df,dummies],axis=1)
|
cs |
> 범주형 변수에 대해서는 map함수와 pd.get_dummies를 활용한 범주별 카테고리화가 필요했다.
> 도서 연도 컬럼은 '현대', '근대, '고전'을 각각 0, 1, 2로 변환하고, 국내/외국 컬럼은 '외국', '국내'를 각각 0, 1로 변환하고, 원작 세부 장르 컬럼에 대해서는 더미 변수를 활용해 변환했다.
|
1
2
|
sns.heatmap(df[['대출수', '국내/외국', '도서 연도', '동화', '소설', '희곡', '기타']].corr(method="spearman"),
annot=True, fmt='3.1f', cmap='Greens')
|
cs |
> 독립변수들에 대해서 다중공선성 문제 여부를 파악하기 위해 히트맵으로 상관관계를 알아보았다.

> 히트맵으로 살펴본 결과 눈에 띄게 높은 상관관계를 지닌 변수는 없는 듯 보인다.
|
1
2
3
|
vif = pd.DataFrame()
vif["VIF Factor"] = [variance_inflation_factor(df[['대출수', '국내/외국', '도서 연도', '동화', '소설', '희곡', '기타']].values, i) for i in range(df[['대출수', '국내/외국', '도서 연도', '동화', '소설', '희곡', '기타']].shape[1])]
vif["features"] = df[['대출수', '국내/외국', '도서 연도', '동화', '소설', '희곡', '기타']].columns
|
cs |
> 그리곤 다중 공선성을 알아보는 방법 중 하나인 VIF값을 알아보았다.

> 그 결과 소설 변수의 VIF값이 10 이상으로 찍히므로 다중공선성 문제가 있다고 판단하여 제거하기로 했다.
> 소설 변수 제거 후 다시 찍어보았다.
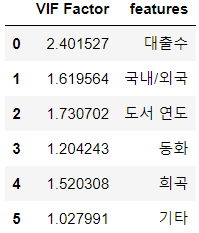
> 변수별로 VIF값들이 재조정되긴 했지만 그 수치가 낮으므로 넘어가기로 한다.
OUTTRO.
후에 나오는 과정은 바로 모델링에 관한 내용들이나 분량이 너무 길다는 판단하에 다음 정리에서 다뤄보고자 한다.
'내가 하는 데이터분석 > 내가 했던 공모전' 카테고리의 다른 글
| 공연예술통합전산망(KOPIS) 빅데이터 분석 공모전 5편 시각화 (0) | 2022.12.23 |
|---|---|
| 공연예술통합전산망(KOPIS) 빅데이터 분석 공모전 4편 모델링 (0) | 2022.12.21 |
| 공연예술통합전산망(KOPIS) 빅데이터 분석 공모전 2편 가설2 (0) | 2022.12.18 |
| 공연예술통합전산망(KOPIS) 빅데이터 분석 공모전 1편 가설1 (0) | 2022.12.16 |



