진행 기간 : 20220801 ~ 20221019
이 전글에선 공모전을 진행하며 전처리에 대한 부분을 정리하며 다뤄보았다.
공연예술통합전산망(KOPIS) 빅데이터 분석 공모전 3편 전처리
진행 기간 : 20220801 ~ 20221019 이 전글에서는 가설2에 대해서 다뤄보면서 정리해 보았다. 공연예술통합전산망(KOPIS) 빅데이터 분석 공모전 2편 가설2 진행 기간 : 20220801 ~ 20221019 이 전에는 가설1에 대
py-moon.tistory.com
앞서 정리한 글에서는 모델링하기 전 진행한 전처리 과정이다.
우리는 모델링 과정에서 여러 분류모델을 비교분석하고, 가장 성능이 좋았던 분류 모델을 선정하는 과정을 거쳤다.
각각의 분류모델에 대해서 어떤 학습을 거쳤는지와 선정한 모델에 대한 이유에 대해서 정리하고자 한다.
그리고 선정된 모델에 대해서 최적의 하이퍼파라미터를 찾는 과정을 거치면서 최종적으로 모델링을 마쳤다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
%matplotlib inline
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import GradientBoostingClassifier
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import *
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
from statsmodels.stats.outliers_influence import variance_inflation_factor
import statsmodels.api as sm
import warnings
warnings.filterwarnings('ignore')
|
cs |
> 모델링에 필요한 모듈과 라이브러리를 미리 불러와준다.
|
1
2
|
X = df[['대출수', '도서 연도','국내/외국', '기타', '동화','희곡']]
Y = df['흥행 여부']
|
cs |
> 독립변수와 종속변수를 df로부터 구분해 주었다.
|
1
|
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.2, random_state=2022)
|
cs |
> train_test_split을 활용해서 8 : 2로 데이터셋을 분할해 줬다.
|
1
2
3
4
5
|
logreg = LogisticRegression()
logreg.fit(x_train, y_train)
y_pred = logreg.predict(x_test)
logreg_cvs = cross_val_score(logreg, X, Y, cv=3, scoring='precision_micro')
print('precision mean :',np.mean(logreg_cvs))
|
cs |
> 첫 번째로 로지스틱 회귀모델을 가지고 학습을 시켜 성능 검증을 진행해 보았다.
> accuracy score는 현재 가지고 있는 데이터의 종속변수의 분포가 불균형이므로 평가지표로서 사용하기가 어렵다는 의견이 있었다.
> 제작/기획사 입장에서 흥행 실패(0)를 흥행 성공(1)으로 예측하면 안 되므로 FP(실제는 0(흥행 실패)인데 예측은 1(흥행 성공))를 낮추는 데에 초점을 맞추는 precision(정밀도)을 평가지표로 사용하기로 했다.
> 종속변수의 분포가 한쪽(흥행 실패)에 쏠려 있는 데이터이므로 균형 잡힌 평균을 구하기 위하여 성능 검증을 위해 micro를 사용했다.
> 그리곤 정밀도의 평균을 구해서 출력하여 볼 수 있도록 하였다.
|
1
|
precision mean : 0.7442922374429224
|
cs |
> 결과는 약 0.74의 정밀도를 기록했다.
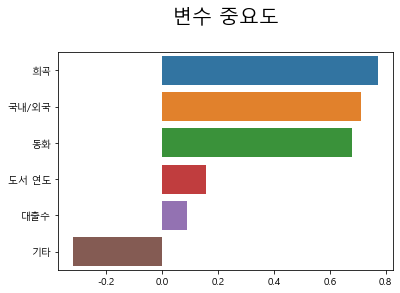
> 로지스틱 회귀모델에 학습된 모형에 대해 독립변수 중 종속변수에 영향을 끼치는 변수를 시각적으로 살펴보기 위해 위처럼 그 결과에 대해 시각화를 해 보았다.
> 희곡 - 국내/외국 - 동화 - 도서 연도 - 대출 수 - 기타 순으로 중요도에 대한 수치가 나타나고 있다.
|
1
2
3
4
5
6
7
8
|
random_forest = RandomForestClassifier()
random_forest.fit(x_train, y_train)
y_pred = random_forest.predict(x_test)
rf_cvs = cross_val_score(random_forest, X, Y, cv=3, scoring='precision_micro')
print('precision mean :',np.mean(rf_cvs))
precision mean : 0.6940639269406392
|
cs |
> 두 번째로 랜덤 포레스트 분류모델을 가지고 학습을 시켜 성능 검증을 진행해 보았다.
> 그 결과는 약 0.69의 정밀도를 기록했다.

> 랜덤 포레스트 분류모델에선 대출 수가 월등하게 영향을 주고 있다고 볼 수 있다.
> 대출 수 - 도서 연도 - 국내/외국 - 동화 - 희곡 - 기타 순으로 나타나고 있다.
|
1
2
3
4
5
6
7
8
|
knn = KNeighborsClassifier()
knn.fit(x_train, y_train)
y_pred = knn.predict(x_test)
knn_cvs = cross_val_score(knn, X, Y, cv=3, scoring='precision_micro')
print('precision mean :',np.mean(knn_cvs))
precision mean : 0.6940639269406392
|
cs |
> 세 번째로 KNN 모델을 가지고 학습을 시켜 성능 검증을 진행해 보았다.
> 그 결과 정밀도 평균이 약 0.69로 나왔다.
|
1
2
3
4
5
6
7
8
|
decision_tree = DecisionTreeClassifier()
decision_tree.fit(x_train, y_train)
y_pred = decision_tree.predict(x_test)
dt_cvs = cross_val_score(decision_tree, X, Y, cv=3, scoring='precision_micro')
print('precision mean :',np.mean(dt_cvs))
precision mean : 0.6621004566210046
|
cs |
> 네 번째로 의사결정나무 분류모델을 가지고 학습을 시켜 성능 검증을 진행해 보았다.
> 결과는 약 0.66의 정밀도를 보여주고 있었다.
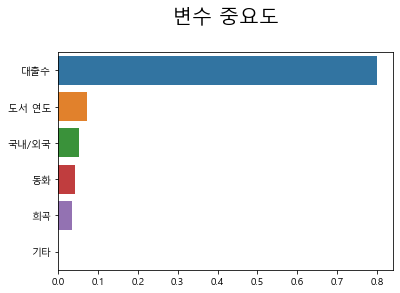
> 의사결정나무에서도 대출 수가 종속변수인 흥행 여부에 영향을 가장 많이 끼치는 것으로 결과가 나왔다.
> 대출 수 - 도서 연도 - 국내/외국 - 동화 - 희곡 - 기타 순으로 나타난다.
|
1
2
3
4
5
6
7
8
|
ada_boost = AdaBoostClassifier()
ada_boost.fit(x_train, y_train)
y_pred = ada_boost.predict(x_test)
ada_cvs = cross_val_score(ada_boost, X, Y, cv=3, scoring='precision_micro')
print('precision mean :',np.mean(ada_cvs))
precision mean : 0.7031963470319634
|
cs |
> 다섯 번째로 AdaBoost 분류모델을 가지고 학습을 시켜 성능 검증을 진행해 보았다.
> 약 0.7의 정밀도를 기록했다.

> AdaBoost에서도 마찬가지로 대출 수가 영향을 끼치는 정도가 압도적이다.
> 대출 수 - 국내/외국 - 기타 - 동화 - 도서 연도순으로 나타나고 있다.
|
1
2
3
4
5
6
7
8
|
gradientboost = GradientBoostingClassifier()
gradientboost.fit(x_train, y_train)
y_pred = gradientboost.predict(x_test)
gb_cvs = cross_val_score(gradientboost, X, Y, cv=3, scoring='precision_micro')
print('precision mean :',np.mean(gb_cvs))
precision mean : 0.6666666666666666
|
cs |
> 여섯 번째로 GradientBoosting 분류모델을 가지고 학습을 시켜 성능 검증을 진행해 보았다.
> 그 결과 정밀도 평균이 약 0.66으로 나왔다.
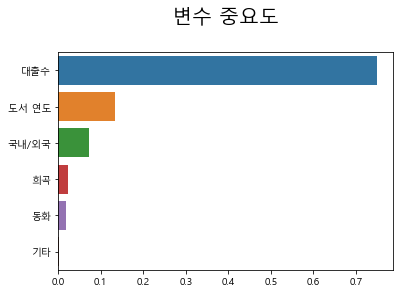
> GradientBoosting 모델 결과도 대출 수가 압도적이다.
> 한 가지 발견한 점이 있다면 대출 수를 제외한 나머지 변수에 대해서는 순위가 모델마다 다르다는 것이다.
> 랜덤 포레스트, 의사결정나무, AdaBoost, GradientBoosting이 모두 대출 수가 압도적인 수치를 기록하고 있는데 나머지 칼럼들은 매 모델마다 그 수치에 따른 순위가 변동되는 것이 의문점으로 다가왔다.
|
1
2
3
4
5
6
7
8
|
xgb = XGBClassifier()
xgb.fit(x_train, y_train)
y_pred = xgb.predict(x_test)
xgb_cvs = cross_val_score(xgb, X, Y, cv=3, scoring='precision_micro')
print('precision mean :',np.mean(xgb_cvs))
precision mean : 0.6757990867579909
|
cs |
> 일곱 번째로 XGB 분류모델을 가지고 학습을 시켜 성능 검증을 진행해 보았다.
> 결과는 약 0.67의 정밀도를 보여주고 있었다.

> XGB에서는 도서 연도 - 동화 - 국내/외국 - 희곡 - 대출 수 - 기타 순으로 나타나고 있지만, 대부분의 변수들이 영향을 많이 끼치고 있다는 결과를 보여주는 듯하다.
> 여기서 순위를 매기는 것은 크게 의미가 없어 보인다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
x = ["1", "2", "3"]
y_logreg = logreg_cvs
y_rf = rf_cvs
y_knn = knn_cvs
y_dt = dt_cvs
y_ada = ada_cvs
y_gb = gb_cvs
y_xgb = xgb_cvs
plt.rcParams['figure.figsize'] = (10, 8)
plt.rcParams['font.size'] = 12
plt.plot(x, y_logreg, label="logisticreg")
plt.plot(x, y_rf, label="randomforest")
plt.plot(x, y_dt, label="decisiontree")
plt.plot(x, y_knn, label='knn')
plt.plot(x, y_ada, label="adaboosting")
plt.plot(x, y_gb, label="gradientboosting")
plt.plot(x, y_xgb, label="xgboosing")
plt.title('모델 비교 그래프')
plt.xlabel("fold")
plt.ylabel("정밀도")
plt.legend()
|
cs |
> 우리는 앞서 살펴본 일곱 가지의 모델에 대해서 교차검증을 실시하였다.
> 이 과정을 통해 최종 모델링에 사용될 모델을 선정하고자 했다.
> 3-fold 교차검증을 실시했고 각 시행마다 모델별 정밀도에 대한 부분을 시각화해 보았다.

> 그래프를 살펴보면 로지스틱 회귀모델이 세 번의 시행 모두 우세한 결과를 보여주고 있다.
> 나머지 모델에 대해서는 정밀도가 크게 감소하거나, 작게 증가하는 형태를 보이고 있으나 로지스틱 회귀모델을 그 차이가 크지 않아 꾸준한 성능을 내고 있다고 해석할 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
params = {
"penalty" : ["l2", "l1"],
"C" : [0.01, 0.1, 1, 5, 10]
}
lr = LogisticRegression()
gs = GridSearchCV(lr, param_grid=params, cv=5, n_jobs=-1, scoring='precision_micro')
gs.fit(x_train, y_train)
print("best param : {}".format(gs.best_params_))
best param : {'C': 0.01, 'penalty': 'l2'}
|
cs |
> 모델의 성능을 좀 더 올리기 위해 최적의 하이퍼파라미터를 GridSearchCV를 통해 찾아보았다.
> 그 결과 penalty는 L2, C는 0.01일 때가 가장 성능이 좋다는 결과가 나왔다.
|
1
2
3
4
5
6
7
8
|
logreg = LogisticRegression(C=0.01, penalty='l2')
logreg.fit(x_train, y_train)
y_pred = logreg.predict(x_test)
logreg_cvs = cross_val_score(logreg, X, Y, cv=3, scoring='precision_micro')
print('precision mean :',round(np.mean(logreg_cvs), 2))
precision mean : 0.75
|
cs |
> 위에서 찾은 하이퍼 파라미터를 가지고 로지스틱 회귀모델을 다시 학습시키고 정밀도 평균을 출려해봤다.
> 결과는 0.75의 정밀도를 기록하고 있다.
> 성능이 좋다고 하기엔 애매한 수치라고 생각했으나 팀 회의 끝에 이 모델을 가져가기로 했다.
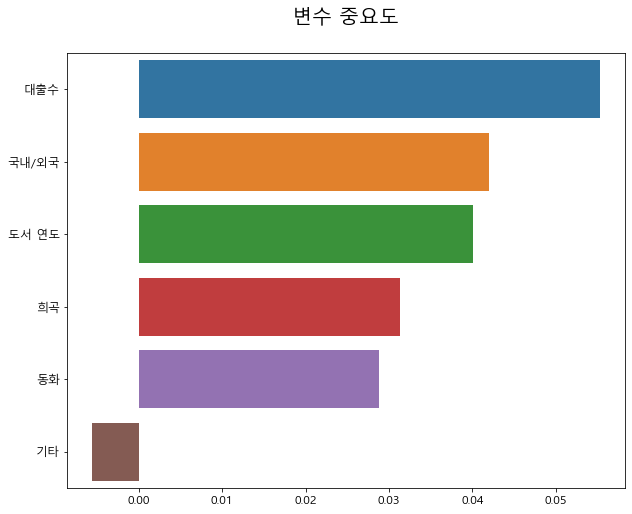
> 최종 모델에 대한 변수 중요도를 나타내는 그래프이다.
> 대출 수 - 국내/외국 - 도서 연도 - 희곡 - 동화 - 기타 순으로 중요도에 대한 수치를 나타내고 있다.
> 결과를 보고 대출 수가 가장 높은 중요도를 나타내고 있어서 예상한 결과대로 나와서 참 다행이라는 생각을 했다.
'내가 하는 데이터분석 > 내가 했던 공모전' 카테고리의 다른 글
| 공연예술통합전산망(KOPIS) 빅데이터 분석 공모전 5편 시각화 (0) | 2022.12.23 |
|---|---|
| 공연예술통합전산망(KOPIS) 빅데이터 분석 공모전 3편 전처리 (0) | 2022.12.20 |
| 공연예술통합전산망(KOPIS) 빅데이터 분석 공모전 2편 가설2 (0) | 2022.12.18 |
| 공연예술통합전산망(KOPIS) 빅데이터 분석 공모전 1편 가설1 (0) | 2022.12.16 |



