단일 결정트리의 단점을 극복하기 위해 여러 머신러닝 모델을 연결하여 더 강력한 모델을 방법인 앙상블(Ensemble)에 대해서 알아보자.
이 전의 머신러닝에서 우리는 앙상블 기법 중에서 부스팅(Boosting)에 대해서 다뤄보며 분류 알고리즘뿐 아니라 회귀 알고리즘에 대해서도 알아보았다.
앙상블(Ensemble) - Boosting with Python
단일 결정트리의 단점을 극복하기 위해 여러 머신러닝 모델을 연결하여 더 강력한 모델을 방법인 앙상블(Ensemble)에 대해서 알아보자. 이 전의 머신러닝에서 우리는 앙상블 기법 중에서 배깅(Baggi
py-moon.tistory.com
앙상블 기법에는 기본적으로 배깅(Bagging, Bootstrap Aggregating), 부스팅(Boosting), 랜덤포레스트(RandomForest)가 있다.
오늘 다뤄볼 앙상블 기법 중 랜덤포레스트(RandomForest)는 배깅과 부스팅보다 더 많은 무작위성을 주어 약한 학습기들을 생성한 후 이를 선형결합하여 최종 학습기를 만드는 방법이다.
별도의 변수 제거 없이 모델링하므로 정확도 측면에서 좋은 성과를 보이는 기법 중 하나이다.
이론적인 설명이나 최종결과에 대한 해석이 어렵다는 단점이 있지만,
예측력이 매우 높은 것으로 알려져 있다. 입력변수가 많은 경우 배깅 및 부스팅과 비슷하거나 더 좋은 예측력을 보인다.
그렇다면 바로 데이터를 가지고 직접 실습해보자.
첫 번째로 랜덤포레스트로 분류분석을 진행해 보자.
사용할 데이터로는 캐글에서 지원하는 유방암 데이터를 활용한다.
|
1
2
3
4
5
6
7
8
9
10
|
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score, f1_score
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import plot_roc_curve, roc_auc_score
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings(action='ignore')
breast = pd.read_csv('data/breast-cancer.csv')
|
cs |
> 분류분석을 진행하기 위한 라이브러리와 데이터셋을 불러와준다.
|
1
2
3
4
5
6
7
8
9
10
|
breast['diagnosis'] = np.where(breast['diagnosis'] == 'M', 1, 0)
x = breast[['area_mean', 'texture_mean']]
y = breast['diagnosis']
train_x, test_x, train_y, test_y = train_test_split(x, y, stratify = y, test_size = 0.3, random_state = 42)
print(train_x.shape, test_x.shape, train_y.shape, test_y.shape)
(398, 2) (171, 2) (398,) (171,)
|
cs |
> 종속변수를 One-Hot Encoding으로 수치형 자료로 변환한다.
> 모델 학습에 사용할 데이터를 마련하기 위해 데이터셋을 분할해 준 후, 각각의 shape을 확인해 본다.
|
1
2
3
4
5
6
7
8
|
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(n_estimators = 100, min_samples_split = 5)
pred = clf.fit(train_x, train_y).predict(test_x)
print('정확도 : {:.2f}'.format(clf.score(test_x, test_y)))
정확도 : 0.91
|
cs |
> RandomForestClassifier의 객체를 불러온다.
> 모델의 하이퍼파라미터인 n_estimators는 RandomForest에서 나무의 수를 뜻하며 default = 100이다.
> 그리고 min_samples_split은 내부 노드를 분할하는데 필요한 최소 샘플의 개수로 default = 2이다.
> 모델을 학습시키고 예측값을 pred에 저장한다.
> score메서드를 통해서 모델의 평균 정확도를 확인한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score, f1_score
test_cm = confusion_matrix(test_y, pred)
test_acc = accuracy_score(test_y, pred)
test_prc = precision_score(test_y, pred)
test_rcll = recall_score(test_y, pred)
test_f1 = f1_score(test_y, pred)
print(test_cm)
print('\n')
print('정확도 : {:.2f}%'.format(test_acc*100))
print('정밀도 : {:.2f}%'.format(test_prc*100))
print('재현율 : {:.2f}%'.format(test_rcll*100))
print('F1-score : {:.2f}%'.format(test_f1*100))
[[104 3]
[ 13 51]]
정확도 : 90.64%
정밀도 : 94.44%
재현율 : 79.69%
F1-score : 86.44%
|
cs |
> 분류 분석에서 사용하는 혼동행렬을 기반으로 하는 여러 가지 성능평가지표를 가져온다.
> 위 결과처럼 여러 평가지표를 통해서 모델의 성능을 파악한다.
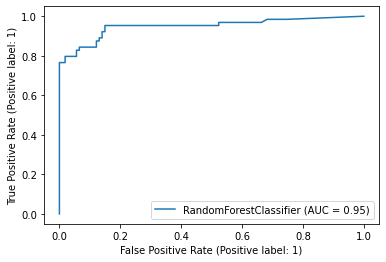
> 마찬가지로 성능평가에 쓰이는 지표인 ROC곡선과 AUC값을 구해볼 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
|
importances = clf.feature_importances_
column_nm = pd.DataFrame(['area_mean', 'texture_mean'])
feature_importances = pd.concat([column_nm, pd.DataFrame(importances)], axis = 1)
feature_importances.columns = ['feature_nm', 'importances']
print(feature_importances)
feature_nm importances
0 area_mean 0.721879
1 texture_mean 0.278121
|
cs |
> 종속변수의 예측에 영향을 주는 변수를 알아보기 위해 변수 중요도를 구해볼 수 있다.
> 결과를 보면 area_mean변수가 종속변수의 예측에 큰 부분을 차지한다고 볼 수 있다.

> 변수중요도의 결과인 수치를 그래프를 통해서 시각화해 볼 수도 있다.
두 번째로 랜덤포레스트를 활용해서 회귀분석을 진행해 보자.
사용할 데이터로는 캐글에서 지원하는 자동차 데이터를 활용한다.
|
1
2
3
4
5
6
7
8
9
|
from sklearn.metrics import mean_squared_error, mean_absolute_error, mean_squared_error
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings(action='ignore')
car = pd.read_csv('data/CarPrice_Assignment.csv')
|
cs |
> 먼저, 회귀분석에 필요한 라이브러리와 데이터셋을 불러와준다.
|
1
2
3
4
5
6
7
8
9
10
|
car_num = car.select_dtypes(['number'])
features = list(car_num.columns.difference(['car_ID', 'symboling', 'price']))
x = car_num[features]
y = car_num['price']
train_x, test_x, train_y, test_y = train_test_split(x, y, test_size = 0.3, random_state = 42)
print(train_x.shape, test_x.shape, train_y.shape, test_y.shape)
(143, 13) (62, 13) (143,) (62,)
|
cs |
> 독립변수와 종속변수를 정의하고, 모델 학습을 위해서 데이터셋을 분할해 준다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
from sklearn.metrics import mean_squared_error, mean_absolute_error, mean_squared_error
from sklearn.ensemble import RandomForestRegressor
reg = RandomForestRegressor()
pred = reg.fit(train_x, train_y).predict(test_x)
print('MSE :', round(mean_squared_error(test_y, pred), 2))
print('MAE :', round(mean_absolute_error(test_y, pred), 2))
print('RMSE :', round(np.sqrt(mean_squared_error(test_y, pred)), 2))
print('Accuracy : {:.2f}%'.format(reg.score(test_x, test_y)*100))
MSE : 3869153.16
MAE : 1357.34
RMSE : 1967.02
Accuracy : 94.42%
|
cs |
> 회귀분석에서 오차에 대한 수치를 기반으로 하는 다양한 성능평가지표를 불러온다.
> 위 결과와 같이 모델에 대한 성능을 파악할 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
importances = reg.feature_importances_
column_nm = pd.DataFrame(features)
feature_importances = pd.concat([column_nm, pd.DataFrame(importances)], axis = 1)
feature_importances.columns = ['feature_nm', 'importances']
print(feature_importances)
feature_nm importances
0 boreratio 0.006825
1 carheight 0.004609
2 carlength 0.018006
3 carwidth 0.027142
4 citympg 0.015213
5 compressionratio 0.005578
6 curbweight 0.156175
7 enginesize 0.561938
8 highwaympg 0.152315
9 horsepower 0.030378
10 peakrpm 0.008662
11 stroke 0.004523
12 wheelbase 0.008637
|
cs |
> 변수중요도를 통해서 종속변수의 예측에 중요한 변수들을 확인할 수 있다.
> 변수가 많아서 가독성이 떨어지므로, 중요도의 차이를 알아보기 위해 시각화해보자.
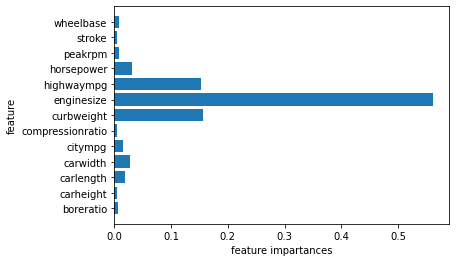
> 변수중요도의 중요도를 그래프로 나타낸 것이다.
> enginesize변수가 압도적으로 높은 중요도를 가지고 있다고 해석할 수 있다.
OUTTRO.
실습 전에 설명한 랜덤포레스트의 이론설명에서 언급했듯이, 별도의 변수 제거 없이 모델링하므로 변수의 개수가 다른 모델에 비해 상대적으로 많다는 특징을 가지고 있다.
이런 특징이 정확도 측면에서 좋은 성과를 보일 수 있다는 장점을 가지고 온다.
하지만 이러한 장점이 단점으로 보일 수 있는 것이 결과에 대한 해석이 복잡하다는 것이다.
그럼에도 내 경험상 랜덤포레스트는 분류분석이나 회귀분석에 있어서 꼭 들어가는 대표적인 모델임에 틀림없다.
'내가 하는 데이터분석 > 내가 하는 머신러닝' 카테고리의 다른 글
| [나이브 베이즈 분류, Naive Bayes Classification] - MultinomialNB with Python (0) | 2023.02.17 |
|---|---|
| [나이브 베이즈 분류, Naive Bayes Classification] - GaussianNB with Python (0) | 2023.02.15 |
| [앙상블, Ensemble] - Boosting with Python (0) | 2023.02.11 |
| [앙상블, Ensemble] - Bagging with Python (0) | 2023.02.09 |
| [K-최근접 이웃, K-Nearest Neighbor] KNN with Python (0) | 2023.02.07 |



