유사한 특성을 가진 데이터는 유사한 범주에 속하는 경향이 있다는 가정으로 데이터를 분류하는 K-최근접 이웃(KNN)에 대해서 정리해 보자.
이 전의 머신러닝에서는 초평면과 마진의 개념으로 분류와 회귀를 지원하는 서포트 벡터 머신(Support Vector Machine)에 대해서 정리해 보았다.
서포트 벡터 머신(Support Vector Machine) with Python
새로운 데이터가 입력되었을 때, 기존 데이터를 활용해서 분류하는 방법인 서포트 벡터 머신(Support Vector Machine)에 대해서 다뤄보자. 이 전의 머신러닝에서는 로지스틱 회귀를 이용해서 이진 분
py-moon.tistory.com
KNN의 기본원리는 이러하다.
학습데이터를 그대로 저장한 뒤 새로운 데이터 포인트에 대해 학습데이터에서 가장 가까운 k개의 데이터 포인트를 찾아 그것들로부터 새로운 데이터 포인트의 범주를 라벨링 한다.
그럼 데이터를 통해서 KNN의 분류와 회귀를 실습해 보자.
첫 번째로 KNN을 활용한 분류 알고리즘은 캐글에서 지원하는 indian_liver_patient데이터를 가지고 진행한다.
|
1
2
3
4
5
6
|
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings(action='ignore')
liver = pd.read_csv('data/indian_liver_patient.csv')
|
cs |
> 분류를 진행하기 위해 필요한 라이브러리와 데이터를 불러와준다.
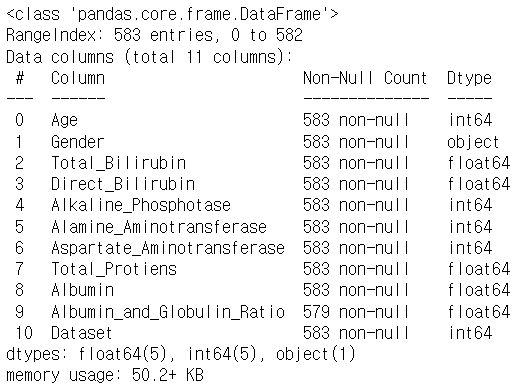
> head()를 찍어서 보여주고 싶었지만 변수들의 이름이 길어서 페이지를 넘어가는 바람에 info()로 대체하며 데이터의 현황을 파악한다.
|
1
|
liver.Gender = np.where(liver.Gender == 'Female', 0, 1)
|
cs |
> 변수들 중 유일하게 object형을 가지는 Gender 변수에 대해서 수치형으로 변환해 주기 위해 One-hot Encoding을 진행한다.

> One-hot Encoding을 진행한 후 데이터 현황이다.
> Gender변수가 수치형으로 바뀐 모습을 확인할 수 있다.

> info()에서 결측치가 있어 보여서 결측치 검사를 해보니 4개의 결측치를 확인하였다.

> 대체하기에는 그 수가 적어 보여 그냥 결측치가 포함되어 있는 행을 제거함으로써 결측치를 제거하였다.
|
1
2
3
4
5
6
7
8
9
10
|
from sklearn.model_selection import train_test_split
x = liver[liver.columns.difference(['Dataset'])]
y = liver['Dataset']
train_x, test_x, train_y, test_y = train_test_split(x, y, stratify = y, test_size = 0.3, random_state = 42)
print(train_x.shape, test_x.shape, train_y.shape, test_y.shape)
(405, 10) (174, 10) (405,) (174,)
|
cs |
> 모델 학습을 위해 데이터셋을 분리해 주는 분할작업을 거친다.
> 종속변수는 Dataset변수이고, 독립변수는 종속변수를 제외한 나머지 변수이다.
> 학습 데이터와 테스트 데이터를 각각 7 : 3 비율로 분할해 준다.
|
1
2
3
4
|
from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier(n_neighbors = 15, weights = 'uniform')
clf.fit(train_x, train_y)
|
cs |
> 모델을 불러와 객체를 생성한다.
> 여기서 하이퍼 파라미터인 k의 값을 15로 조정함으로써 새로운 데이터에 대한 데이터 분류조건 개수를 15개로 한다.
> 모델 학습까지 진행한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score, f1_score
pred = clf.predict(test_x)
test_cm = confusion_matrix(test_y, pred)
test_acc = accuracy_score(test_y, pred)
test_prc = precision_score(test_y, pred)
test_rcll = recall_score(test_y, pred)
test_f1 = f1_score(test_y, pred)
print(test_cm)
print('\n')
print('정확도 : {:.2f}%'.format(test_acc*100))
print('정밀도 : {:.2f}%'.format(test_prc*100))
print('재현율 : {:.2f}%'.format(test_rcll*100))
print('F1-score : {:.2f}%'.format(test_f1*100))
[[112 12]
[ 39 11]]
정확도 : 70.69%
정밀도 : 74.17%
재현율 : 90.32%
F1-score : 81.45%
|
cs |
> 분류 분석에서 사용하는 성능평가지표를 불러와 해당 모델의 성능을 확인해 본다.
> 해당 모델의 분류 정확도는 약 70%를 가진다고 해석할 수 있다.
두 번째로 KNN을 활용한 회귀 알고리즘은 numpy를 활용한 데이터를 가지고 진행한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
np.random.seed(0)
x = np.sort(5 * np.random.rand(400, 1), axis = 0)
T = np.linspace(0, 5, 500)[:, np.newaxis]
print(x[:5], '\n')
print(T[:5])
[[0.02347738]
[0.05713729]
[0.05857042]
[0.06618429]
[0.08164251]]
[[0. ]
[0.01002004]
[0.02004008]
[0.03006012]
[0.04008016]]
|
cs |
> nunpy를 통해서 임의로 난수 데이터를 생성한 값을 x로 활용한다.
|
1
2
3
4
5
6
7
8
9
10
|
y = np.sin(x).ravel()
print(y[:5], '\n')
y[::1] += 1 * (0.5 - np.random.rand(400))
print(y[:5])
[0.02347522 0.05710621 0.05853694 0.06613598 0.08155185]
[ 0.48348242 -0.0825989 0.15023403 0.18872941 -0.22781313]
|
cs |
> 타깃데이터인 y값에는 노이즈를 추가한다.
|
1
2
3
4
5
6
7
|
from sklearn.model_selection import train_test_split
train_x, test_x, train_y, test_y = train_test_split(x, y, test_size = 0.3, random_state = 42)
print(train_x.shape, test_x.shape, train_y.shape, test_y.shape)
(280, 1) (120, 1) (280,) (120,)
|
cs |
> 임의로 데이터를 생성했기 때문에 별다른 전처리는 진행하지 않고 모델링을 진행한다.
> 모델 학습을 위해 데이터를 7: 3으로 분할해 준다.
|
1
2
3
4
5
6
7
|
from sklearn.neighbors import KNeighborsRegressor
knn_uni = KNeighborsRegressor(n_neighbors = 20, weights = 'uniform')
knn_dis = KNeighborsRegressor(n_neighbors = 20, weights = 'distance')
knn_uni.fit(train_x, train_y)
knn_dis.fit(train_x, train_y)
|
cs |
> 두 가지의 모델을 사용하여 성능을 비교분석 할 텐데, 공통적으로 k갑은 20으로 맞춰준다.
> 그리고 weight값의 uniform은 각 이웃의 포인트에 동일한 가중치가 부여되는 것이고, distance는 거리의 영수로 가중치가 부여되며 샘플 포인트에서 가까운 데이터가 멀리 있는 데이터보다 큰 영향을 미친다는 개념으로 접근하는 것이다.
> 모델 학습까지 진행해 준다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
from sklearn.metrics import mean_squared_error, mean_absolute_error
uni_pred = knn_uni.predict(test_x)
dis_pred = knn_dis.predict(test_x)
preds = [uni_pred, dis_pred]
weights = ['Uniform', 'Distance']
evls = ['MSE', 'RMSE', 'MAE']
results = pd.DataFrame(index = weights, columns = evls)
for pred, nm in zip(preds, weights):
mse = mean_squared_error(test_y, pred)
mae = mean_absolute_error(test_y, pred)
rmse = np.sqrt(mse)
results.loc[nm]['MSE'] = round(mse, 2)
results.loc[nm]['RMSE'] = round(rmse, 2)
results.loc[nm]['MAE'] = round(mae, 2)
results
|
cs |
> 학습까지 진행한 두 모델을 가지고 회귀분석에서 사용되는 성능평가지표를 통해서 성능을 비교해 본다.
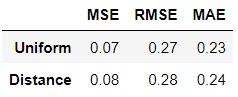
> 결과를 비교해 보니 미미한 차이로 uniform으로 학습한 모델이 성능에서 우수하다는 해석이 가능하다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import matplotlib.pyplot as plt
plt.figure(figsize = (8, 5))
for i, weights in enumerate(['uniform', 'distance']):
knn = KNeighborsRegressor(n_neighbors = 20, weights = weights)
y_ = knn.fit(x, y).predict(T)
plt.subplot(2, 1, i + 1)
plt.scatter(x, y, color = 'darkorange', label = 'data')
plt.plot(T, y_, color='navy', label = 'prediction')
plt.axis('tight')
plt.legend()
plt.title('KNeighborRegressor (k = %i, weights = %s)'%(20, weights))
plt.tight_layout()
|
cs |
> 성능을 시각화해서 두 모델을 비교해 보자.
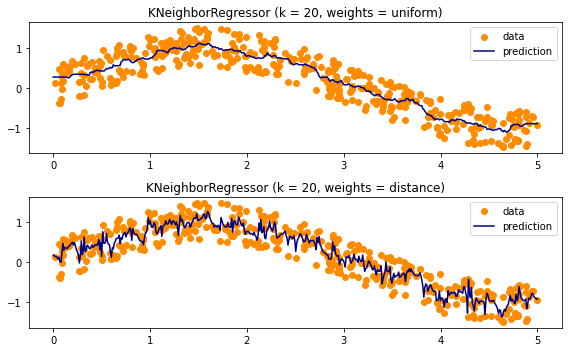
> uniform을 사용한 모델과 distance를 사용한 모델 사이에 prediction에서 차이가 있음을 확인할 수 있다.
OUTTRO.
KNN을 활용해서 분류와 회귀를 실습해 보았다.
KNN의 기본 원리를 떠올리면 회귀보다는 분류에 더 적합한 알고리즘으로 생각할 수 있다. 그랬다.
하지만 회귀 실습도 해보는 시간과 글이었다.
KNN은 기본적으로 데이터 사이의 거리를 측정하는 거리기반 머신러닝 알고리즘에 해당한다.
다양한 거리거리계산식 중에서 KNN은 유클리디안 거리는 많이 사용한다.
이전 글인 SVM도 거리기반이고, 비지도학습 머신러닝 알고리즘 중에서도 군집분석을 포함한 몇몇 기법들이 존재한다.
'내가 하는 데이터분석 > 내가 하는 머신러닝' 카테고리의 다른 글
| [앙상블, Ensemble] - Boosting with Python (0) | 2023.02.11 |
|---|---|
| [앙상블, Ensemble] - Bagging with Python (0) | 2023.02.09 |
| [서포트 벡터 머신, Support Vector Machine] SVM with Python (2) | 2023.02.05 |
| [로지스틱 회귀, Logistic Regression] with Python (6) | 2023.02.03 |
| [다중 회귀, Multiple Regression] with Python (0) | 2023.02.01 |



