단일 결정트리의 단점을 극복하기 위해 여러 머신러닝 모델을 연결하여 더 강력한 모델을 방법인 앙상블(Ensemble)에 대해서 알아보자.
이 전의 머신러닝에서 우리는 앙상블 기법 중에서 배깅(Bagging)에 대해서 다뤄보며 분류 알고리즘뿐 아니라 회귀 알고리즘에 대해서도 알아보았다.
앙상블(Ensemble) - Bagging with Python
단일 결정트리의 단점을 극복하기 위해 여러 머신러닝 모델을 연결하여 더 강력한 모델을 방법인 앙상블(Ensemble)에 대해서 알아보자. 이 전의 머신러닝에서 우리는 K-최근접 이웃(K-Nearest Neighbor,
py-moon.tistory.com
앙상블 기법에는 기본적으로 배깅(Bagging, Bootstrap Aggregating), 부스팅(Boosting), 랜덤포레스트(RandomForest)가 있다.
오늘은 예측력이 약한 모형들을 결합해 강한 예측모형을 만드는 방법인 부스팅(Boosting)에 대해서 알아보자.
지난번에 다뤘던 배깅과의 차이점이 있다면,
배깅은 붓스트랩을 병렬로 수행해서 각 모델을 독립적으로 구축하지만, 부스팅은 순차적인 방식으로 학습을 진행한다는 점이다.
부스팅은 분류결과가 좋지 않은 데이터는 높은 가중치를, 분류 결과가 좋은 데이터는 낮은 가중치를 할당 받는다. 높은 가중치를 받은 데이터 샘플은 다음 붓스트래핑에서 추출될 확률이 높아진다.
이것이 바로 예측력이 약했던 부분을 다음단계에서 개선해 나간다는 개념인 것이다.
따라서 배깅에 비해 모델의 장점을 최적화하고 train데이터에 대해 오류가 적은 결합모델을 생성할 수 있다는 장점이 있지만, train데이터에 과적합 될 위험이 있다.
첫 번째로 진행할 부스팅을 활용한 분류 실습은 캐글에서 지원하는 유방암 데이터를 가지고 진행한다.
|
1
2
3
4
5
6
7
8
9
10
|
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score, f1_score
from sklearn.model_selection import train_test_split
from sklearn.ensemble import AdaBoostClassifier
from sklearn.metrics import plot_roc_curve, roc_auc_score
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings(action='ignore')
breast = pd.read_csv('data/breast-cancer.csv')
|
cs |
> 분류 알고리즘 실습에 필요한 라이브러리와 데이터를 불러와준다.
|
1
2
3
4
5
6
7
8
9
10
|
breast['diagnosis'] = np.where(breast['diagnosis'] == 'M', 1, 0)
x = breast[['area_mean', 'texture_mean']]
y = breast['diagnosis']
train_x, test_x, train_y, test_y = train_test_split(x, y, stratify = y, test_size = 0.3, random_state = 42)
print(train_x.shape, test_x.shape, train_y.shape, test_y.shape)
(398, 2) (171, 2) (398,) (171,)
|
cs |
> 독립변수는 area_mean변수와 texture_mean변수이고, 종속변수는 diagnosis변수이다.
> 종속변수를 수치형 자료형으로 변환하기 위해 One-Hot Encoding을 활용한다.
> 모델 학습을 위해 데이터셋을 훈련용 데이터와 테스트용 데이터를 각각 7 : 3으로 분할해준다.
|
1
2
3
4
5
6
7
8
|
from sklearn.ensemble import AdaBoostClassifier
clf = AdaBoostClassifier(base_estimator = None)
pred = clf.fit(train_x, train_y).predict(test_x)
print('정확도 : {:.2f}'.format(clf.score(test_x, test_y)))
정확도 : 0.91
|
cs |
> 부스팅 방식으로 분류분석을 구현하는 AdaBoostClassifier를 활용한다.
> 분할해 준 데이터를 모델학습에 사용하고, pred에 예측값을 저장해 준다.
> AdaBoostClassifier.score()를 통해서 해당 모델의 평균 정확도를 확인한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score, f1_score
test_cm = confusion_matrix(test_y, pred)
test_acc = accuracy_score(test_y, pred)
test_prc = precision_score(test_y, pred)
test_rcll = recall_score(test_y, pred)
test_f1 = f1_score(test_y, pred)
print(test_cm)
print('\n')
print('정확도 : {:.2f}%'.format(test_acc*100))
print('정밀도 : {:.2f}%'.format(test_prc*100))
print('재현율 : {:.2f}%'.format(test_rcll*100))
print('F1-score : {:.2f}%'.format(test_f1*100))
[[105 2]
[ 13 51]]
정확도 : 91.23%
정밀도 : 96.23%
재현율 : 79.69%
F1-score : 87.18%
|
cs |
> 분류분석에서 사용하는 혼동행렬을 포함, 다양한 성능평가지표를 가져와서 모델의 성능을 자세하게 살펴보자.
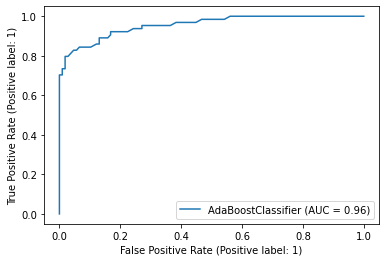
> 마찬가지로 분류분석에서 사용하는 평가지표로서 ROC곡선과 AUC값에 대해 살펴보며 모델의 성능에 대해 자세하게 알 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
|
importances = clf.feature_importances_
column_nm = pd.DataFrame(['area_mean', 'texture_mean'])
feature_importances = pd.concat([column_nm, pd.DataFrame(importances)], axis = 1)
feature_importances.columns = ['feature_nm', 'importances']
print(feature_importances)
feature_nm importances
0 area_mean 0.58
1 texture_mean 0.42
|
cs |
> 변수중요도를 통해서 예측에 사용된 변수들 중 종속변수에 영향을 가장 많이 준 변수가 무엇인지도 확인할 수 있다.
> area_mean변수가 종속변수에 영향을 더 많이 주었다고 해석할 수 있다.
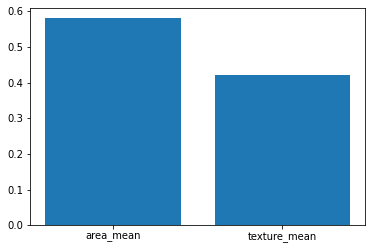
> 위 변수중요도 결과에 대해 막대그래프로 시각화를 해보았다.
두 번째로 진행할 부스팅을 활용한 회귀 실습은 캐글에서 지원하는 자동차 데이터를 가지고 자동차의 가격을 예측하며 진행한다.
> 아래의 회귀 분석 과정들은 분류 분석을 진행할 때 거쳤던 과정과 흡사하다.
|
1
2
3
4
5
6
7
8
9
|
from sklearn.metrics import mean_squared_error, mean_absolute_error, mean_squared_error
from sklearn.ensemble import AdaBoostRegressor
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings(action='ignore')
car = pd.read_csv('data/CarPrice_Assignment.csv')
|
cs |
> 부스팅을 활용한 회귀분석 실습을 위해 필요한 라이브러리와 데이터를 불러와준다.
|
1
2
3
4
5
6
7
8
9
10
|
car_num = car.select_dtypes(['number'])
features = list(car_num.columns.difference(['car_ID', 'symboling', 'price']))
x = car_num[features]
y = car_num['price']
train_x, test_x, train_y, test_y = train_test_split(x, y, test_size = 0.3, random_state = 42)
print(train_x.shape, test_x.shape, train_y.shape, test_y.shape)
(143, 13) (62, 13) (143,) (62,)
|
cs |
> 독립변수는 데이터셋에서 수치형에 해당하는 모든 변수들이고, 종속변수는 price변수이다.
> 데이터셋을 모델학습을 위해 분할해 준다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
from sklearn.metrics import mean_squared_error, mean_absolute_error, mean_squared_error
from sklearn.ensemble import AdaBoostRegressor
reg = AdaBoostRegressor(base_estimator = None)
pred = reg.fit(train_x, train_y).predict(test_x)
print('MSE :', round(mean_squared_error(test_y, pred), 2))
print('MAE :', round(mean_absolute_error(test_y, pred), 2))
print('RMSE :', round(np.sqrt(mean_squared_error(test_y, pred)), 2))
print('Accuracy : {:.2f}%'.format(reg.score(test_x, test_y)*100))
MSE : 6476454.33
MAE : 1993.93
RMSE : 2544.89
Accuracy : 90.65%
|
cs |
> 회귀분석에서 쓰이는 다양한 성능평가지표를 불러와서 회귀 모델에 대해서 성능을 살펴본다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
importances = reg.feature_importances_
column_nm = pd.DataFrame(features)
feature_importances = pd.concat([column_nm, pd.DataFrame(importances)], axis = 1)
feature_importances.columns = ['feature_nm', 'importances']
print(feature_importances)
feature_nm importances
0 boreratio 0.021022
1 carheight 0.008275
2 carlength 0.030350
3 carwidth 0.085941
4 citympg 0.010490
5 compressionratio 0.003960
6 curbweight 0.068035
7 enginesize 0.550607
8 highwaympg 0.053177
9 horsepower 0.135478
10 peakrpm 0.001948
11 stroke 0.015091
12 wheelbase 0.015626
|
cs |
> 종속변수인 price변수의 예측에 영향을 많이 끼치는 변수를 알아보기 위해 변수중요도를 살펴본다.
> 결과를 보니 enginesize변수가 종속변수 예측에 영향이 가장 큰 것으로 해석이 가능하다.
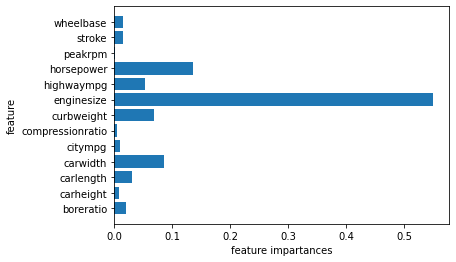
> 수치로 되어있는 결과를 가독성이 뛰어난 시각자료로도 살펴보자.
OUTTRO.
위에서 다뤄보았던 평가지표에 대해서 간단하게 정리해 보자.
분류분석에서 사용하는 평가지표로는
기본적으로 혼동행렬에서 산출할 수 있는 여러 가지 지표가 있고, ROC곡선과 그 아래 면적에 해당하는 AUC값이 있다.
회귀분석에서 사용하는 평가지표로는
오차에 대한 기준으로 많이 쓰이는데 MSE(Mean Squared Error), MAE(Mean Absolute Error), RMSE(Root Mean Squared Error)가 대표적이다.
'내가 하는 데이터분석 > 내가 하는 머신러닝' 카테고리의 다른 글
| [나이브 베이즈 분류, Naive Bayes Classification] - GaussianNB with Python (0) | 2023.02.15 |
|---|---|
| [앙상블, Ensemble] - RandomForest with Python (0) | 2023.02.13 |
| [앙상블, Ensemble] - Bagging with Python (0) | 2023.02.09 |
| [K-최근접 이웃, K-Nearest Neighbor] KNN with Python (0) | 2023.02.07 |
| [서포트 벡터 머신, Support Vector Machine] SVM with Python (2) | 2023.02.05 |



