분석 진행 기간 : 2022.12.21 ~ 2022.12.31
INTRO.
타이타닉 생존자 예측하는 분석과제는 올해 초에 캐글을 처음 접하면서 처음 해본 분석과제로 기억한다.
지금 하는 분석과의 차이점이 있다면 그땐 주로 베이스라인 코드를 보며 배우는 성격이 강했다면, 지금은 대부분 내 머릿속에서 나오는 아이디어로 이루어져 있다.
물론 아직 모르는 부분이 많기 때문에 구글링은 필수적이다. 너무 본인만의 방식을 고집하는 것은 좋지 않기 때문이다.
이 전글에선 DACON - 서울시 따릉이 대여량 예측 분석과제를 수행하고 정리해 보았다.
DACON - 서울시 따릉이 대여량 예측(회귀)
이 전엔 DACON-와인 품질 분류 분석과제를 수행해보고 복습해보았다. DACON - 와인 품질 분류(분류) 두 달 전쯤 처음 데이콘을 접하며 접근하기 쉬운 초급대회를 선정하여 내 수준을 알아보고, 복습
py-moon.tistory.com
데이터셋 확인 및 전처리와 EDA를 진행해보고자 한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
train = pd.read_csv('C:/Users/k1560/Desktop/Titanic/train.csv')
test = pd.read_csv('C:/Users/k1560/Desktop/Titanic/test.csv')
submission = pd.read_csv('C:/Users/k1560/Desktop/Titanic/submission.csv')
# PassengerID : 탑승객 고유 아이디
# Survival : 탑승객 생존 유무 (0: 사망, 1: 생존)
# Pclass : 등실의 등급
# Name : 이름
# Sex : 성별
# Age : 나이
# Sibsp : 함께 탐승한 형제자매, 아내, 남편의 수
# Parch : 함께 탐승한 부모, 자식의 수
# Ticket :티켓 번호
# Fare : 티켓의 요금
# Cabin : 객실번호
# Embarked : 배에 탑승한 항구 이름 ( C = Cherbourn, Q = Queenstown, S = Southampton)
print(train.shape, test.shape, submission.shape)
|
cs |
> Train데이터셋, Test데이터셋, Submission데이터셋을 차례대로 불러오고 각각의 shape을 찍어본다.

> train.head로 상위 5개 데이터 찍어보면서 컬럼과 자료형을 확인한다.
|
1
2
|
train = train.drop(['PassengerId', 'Name', 'Ticket', 'Cabin','Embarked'], axis = 1)
test = test.drop(['PassengerId', 'Name', 'Ticket', 'Cabin', 'Embarked'], axis = 1)
|
cs |
> head로 데이터를 확인한 후 타이타닉호의 생존자 예측에 있어 불필요하다고 생각되거나 정보가 중복되는 변수(PassengerId, Name, Ticket, Cabin, Embarked)는 제거하였다.
|
1
|
train[['Fare']].groupby(train['Pclass']).mean().T
|
cs |
> 데이콘에 공유된 코드들을 살펴보면서 도출하면 좋을 듯한 인사이트에 대해서 살펴보았다.
> 그중 하나가 객실 등급별 티켓의 금액이다. 위 코드를 실행하게 되면 아래의 결과를 볼 수 있다.

> 객실 등급별 티켓의 금액을 살펴본 결과로는
> 1등급 객실의 평균 티켓 금액은 약 84달러
> 2등급 객실의 평균 티켓 금액은 약 20달러
> 3등급 객실의 평균 티켓 금액은 약 13달러로 확인할 수 있었다.
|
1
2
3
4
5
6
|
print(np.percentile(train['Fare'], 92))
# 1등급의 평균 티켓 가격은 총 티켓에 대해 상위 약 8%에 해당한다
print(np.percentile(train['Fare'], 58))
# 2등급은 평균 티켓 가격은 총 티켓에 대해 상위 약 42%에 해당한다.
print(np.percentile(train['Fare'], 45))
# 3등급은 평균 티켓 가격은 총 티켓에 대해 상위 약 55%에 해당한다.
|
cs |
> 각각의 객실 등급별로 해당 티켓의 평균가격이 상위 몇 퍼센트를 차지하는지 궁금해서 한 번 알아보았다.
> 우선, 1등급은 216명, 2등급은 184명, 3등급은 491명으로 분포되어 있었다.
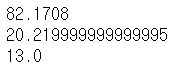
> 수치를 비교해서 확인해 본 결과 1등급의 평균 티켓 가격은 총티켓에 대해 상위 약 8%에 해당한다.
> 2등급의 평균 티켓 가격은 총 티켓에 대해 상위 약 42%에 해당하고, 3등급의 평균 티켓 가격은 총 티켓에 대해 상위 약 55%에 해당한다.
> 이를 통해서 2등급과 3등급 사이에는 큰 차이가 보이진 않지만 1등급과 2등급 사이에는 생각보다 큰 차이가 벌어지는 것을 확인할 수 있었다.
|
1
|
train[['Age']].groupby(train['Pclass']).mean().T
|
cs |
> 그리고 뒤에서 Age변수에 대해서 결측치를 제거해야 해서 객실 등급별 평균 나이를 도출해 보았다.

> 결과로는 1등급 객실의 평균 나이는 약 38세, 2등급 객실의 평균 나이는 약 29세, 3등급 객실의 평균 나이는 약 25세라고 알 수 있었다.
> 3등급 객실에는 상대적으로 젊은 사람들이 많이 탑승해 있었던 것 같다.
|
1
2
3
4
5
6
7
8
9
|
tr_age_1 = train[(train['Pclass'] == 1) & (train['Age'].isnull() == 1)]
tr_age_1['Age'] = tr_age_1['Age'].fillna(39)
tr_age_2 = train[(train['Pclass'] == 2) & (train['Age'].isnull() == 1)]
tr_age_2['Age'] = tr_age_2['Age'].fillna(29)
tr_age_3 = train[(train['Pclass'] == 3) & (train['Age'].isnull() == 1)]
tr_age_3['Age'] = tr_age_3['Age'].fillna(25)
train = train.dropna(subset = ['Age'])
train = pd.concat([train, tr_age_1, tr_age_2, tr_age_3])
|
cs |
> Train데이터셋에서 Age변수에 대한 결측치를 각각의 객실 등급별 평균나이로 대체하여 제거하였다.
|
1
2
3
4
5
6
7
8
9
|
age_1 = test[(test['Pclass'] == 1) & (test['Age'].isnull() == 1)]
age_1['Age'] = age_1['Age'].fillna(39)
age_2 = test[(test['Pclass'] == 2) & (test['Age'].isnull() == 1)]
age_2['Age'] = age_2['Age'].fillna(29)
age_3 = test[(test['Pclass'] == 3) & (test['Age'].isnull() == 1)]
age_3['Age'] = age_3['Age'].fillna(25)
test = test.dropna(subset = ['Age'])
test = pd.concat([test, age_1, age_2, age_3])
|
cs |
> Test데이터셋에서도 동일한 방식으로 Age변수의 결측치를 제거하였다.
|
1
2
3
4
5
6
7
8
9
10
|
train['Sex'] = train['Sex'].map({'male':0, 'female':1})
train['With'] = train['SibSp'] + train['Parch'] + 1
train = train.drop(['SibSp', 'Parch'], axis = 1)
test['Sex'] = test['Sex'].map({'male':0, 'female':1})
test['With'] = test['SibSp'] + test['Parch'] + 1
test = test.drop(['SibSp', 'Parch'], axis = 1)
test['Fare'] = test['Fare'].fillna(13)
|
cs |
> 1, 6줄은 성별을 범주형 변수로 변환하는 코드로 남자는 0, 여자는 1로 변환하였다.
> 2, 7줄은 SibSp(함께 탑승한 형제자매, 아내, 남편의 수) 변수와 Parch(함께 탑승한 부모, 자식의 수)에 1을 더한 값으로 With라는 요약변수를 생성하였다.
> 여기서 With라는 요약변수는 앞의 두 변수가 본인을 포함한 동행을 표현하기 위한 변수라고 판단했기 때문에 본인을 포함한 동승자 수라는 의미에서 생성하였다.
> 3, 8줄은 요약변수를 생성하였기 때문에 불필요하다고 판단하여 제거하였다.
> 마지막으로 10줄은 Test데이터셋에 단 1개만 존재하는 결측값으로 티겟의 요금에 해당하는 변수이다.
> 이 결측값을 제거하기 위해 어디에서 결측이 났는지 확인해 본 결과 3등급 객실 사용자 중 한 명이었다.
> 그래서 3등급 객실의 평균 티켓 금액으로 대체하여 결측치를 제거하였다.
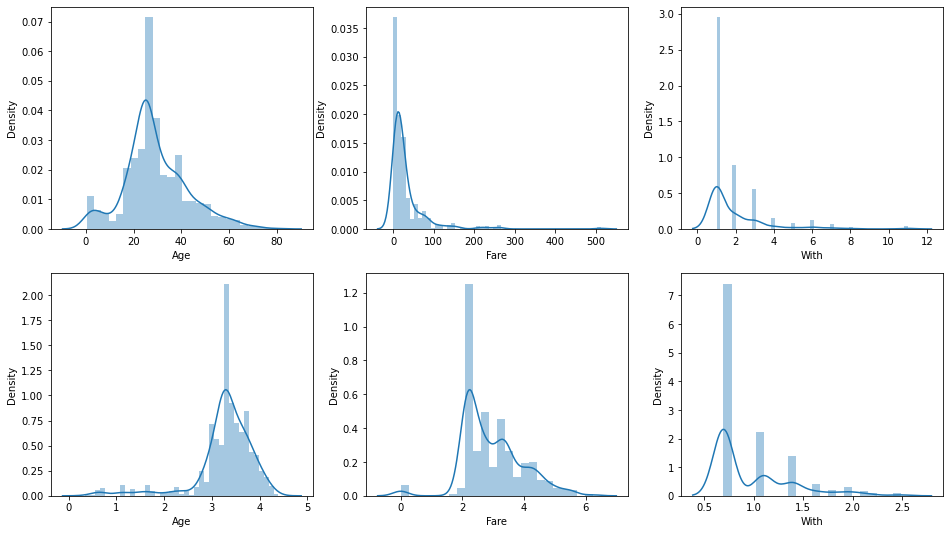
> 마지막 전처리로 수치형 변수들에 대해서 정규성을 확인해 보았다. 그리고 Age, Fare, With 세 변수에 대해서 로그변환 전후 그래프를 찍어보았다.
> 그 결과로는 With 변수는 큰 변화가 없지만, Age 변수와 Fare변수는 로그변환을 하는 것이 낫겠다고 판단했다.
|
1
2
3
4
5
6
7
|
train['Age'] = np.log1p(train['Age'])
train['Fare'] = np.log1p(train['Fare'])
train['With'] = np.log1p(train['With'])
test['Age'] = np.log1p(test['Age'])
test['Fare'] = np.log1p(test['Fare'])
test['With'] = np.log1p(test['With'])
|
cs |
> 따라서, Train데이터셋, Test데이터셋 둘 다 Age, Fare, With변수에 대해 로그변환을 진행해 주었다.
지금부터 모델링을 진행해보고자 한다.
요즘 내가 하는 분석과제들에서 자주 사용하고 있는 방법으로 모델 학습, 데이터셋 분할, 모델 검증, 성능 검증을 동시에 할 수 있는 코드이다.
학습에 사용될 모델만 바꾸면 간편하게 바로바로 확인이 가능하다는 점에서 효율적이다.
하지만 겨우 1년가량 공부한 내가 만든 코드이기에 허점이 많을 것으로 생각되지만 아직까진 발견하진 못했다.
더 좋은 알고리즘이나 방식이 있다면 적극적으로 수용해서 나의 분석과제에 써먹어볼 예정이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
from sklearn.model_selection import cross_val_score
from sklearn.tree import DecisionTreeClassifier
train_x = train.drop(['Survived'], axis=1)
train_y = train['Survived']
dtc = DecisionTreeClassifier()
auc = cross_val_score(dtc, train_x, train_y, scoring='roc_auc', cv = 10)
avg_auc = np.mean(auc)
print('DecisionTreeClassifier 10-folds의 개별 RMSE : ', np.round(auc, 2))
print('DecisionTreeClassifier 10-folds의 평균 RMSE : {0:.2f} '.format(avg_auc))
DecisionTreeClassifier 10-folds의 개별 RMSE : [0.67 0.76 0.75 0.81 0.76 0.77 0.68 0.75 0.82 0.51]
DecisionTreeClassifier 10-folds의 평균 RMSE : 0.73
|
cs |
> 첫 번째 모델은 DecisionTreeClassifier를 사용했고 모델 학습에 사용될 데이터를 분할해 주었다.
> 이번 과제에서 사용된 성능 지표로는 ROC_AUC_SCORE이다.
> 총 10번의 교차검증을 실시했고, 각각의 시행마다 각각 ROC_AUC_SCORE를 list형태로 보여주고 있다.
> 그리고, 마지막엔 평균 ROC_AUC_SCORE를 보여줌으로써 하나의 모델을 마친다.
> 이러한 과정을 아래 총 5가지의 모델을 가지고 동일하게 적용시켜 보았다.
> 15, 16줄에 RMSE -> ROC_AUC_SCORE로 보면 된다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifier
train_x = train.drop(['Survived'], axis=1)
train_y = train['Survived']
rfc = RandomForestClassifier(random_state=2022)
auc = cross_val_score(rfc, train_x, train_y, scoring='roc_auc', cv = 10)
avg_auc = np.mean(auc)
print('RandomForestClassifier 10-folds의 개별 RMSE : ', np.round(auc, 2))
print('RandomForestClassifier 10-folds의 평균 RMSE : {0:.2f} '.format(avg_auc))
RandomForestClassifier 10-folds의 개별 RMSE : [0.79 0.82 0.85 0.87 0.9 0.85 0.81 0.84 0.88 0.84]
RandomForestClassifier 10-folds의 평균 RMSE : 0.85
|
cs |
> 두 번째 모델로 RandomForestClassifier를 사용하였다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
train_x = train.drop(['Survived'], axis=1)
train_y = train['Survived']
lr = LogisticRegression(random_state=2022)
auc = cross_val_score(lr, train_x, train_y, scoring='roc_auc', cv = 10)
avg_auc = np.mean(auc)
print('LogisticRegression 10-folds의 개별 RMSE : ', np.round(auc, 2))
print('LogisticRegression 10-folds의 평균 RMSE : {0:.2f} '.format(avg_auc))
LogisticRegression 10-folds의 개별 RMSE : [0.85 0.85 0.85 0.82 0.87 0.86 0.88 0.77 0.96 0.81]
LogisticRegression 10-folds의 평균 RMSE : 0.85
|
cs |
> 세 번째 모델로 LogisticRegression을 사용하였다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
from sklearn.model_selection import cross_val_score
from sklearn.naive_bayes import GaussianNB
train_x = train.drop(['Survived'], axis=1)
train_y = train['Survived']
nb = GaussianNB()
auc = cross_val_score(nb, train_x, train_y, scoring='roc_auc', cv = 10)
avg_auc = np.mean(auc)
print('GaussianNB 10-folds의 개별 RMSE : ', np.round(auc, 2))
print('GaussianNB 10-folds의 평균 RMSE : {0:.2f} '.format(avg_auc))
GaussianNB 10-folds의 개별 RMSE : [0.77 0.78 0.83 0.78 0.85 0.85 0.91 0.76 0.95 0.88]
GaussianNB 10-folds의 평균 RMSE : 0.84
|
cs |
> 네 번째 모델로 GaussianNB를 사용하였다.
> 이 모델은 나이브 베이지안 개념을 가지고 온 모델이다.
> 이번에 처음 사용해 봤는데 앞으로 자주 써보면서 공부해 봐야겠다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
from sklearn.model_selection import cross_val_score
from sklearn.neighbors import KNeighborsClassifier
train_x = train.drop(['Survived'], axis=1)
train_y = train['Survived']
knn = KNeighborsClassifier(n_neighbors = 3)
auc = cross_val_score(knn, train_x, train_y, scoring='roc_auc', cv = 10)
avg_auc = np.mean(auc)
print('KNeighborsClassifier 10-folds의 개별 RMSE : ', np.round(auc, 2))
print('KNeighborsClassifier 10-folds의 평균 RMSE : {0:.2f} '.format(avg_auc))
KNeighborsClassifier 10-folds의 개별 RMSE : [0.64 0.64 0.69 0.72 0.72 0.74 0.65 0.72 0.79 0.54]
KNeighborsClassifier 10-folds의 평균 RMSE : 0.68
|
cs |
> 다섯 번째로 KNeighborsClassifier모델을 사용하였다.
> 다섯 가지의 모델들은 동일한 과정을 거쳐 성능을 비교해 본 결과, LogisticRegression모델이 약 0.85로 가장 우수한 성능을 가지고 있는 모델로써 최종모델로 선정했다.
> 이 모델의 성능을 조금 더 높여보려 최적의 하이퍼파라미터를 찾아보려 한다.
GridSearchCV를 통해서 모델의 성능을 더 높여보자.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
from sklearn.model_selection import GridSearchCV
params = {"C" : [0.01, 0.1, 1, 5, 10, 50, 100],
"penalty" : ["l1", "l2"]}
lr = LogisticRegression(random_state=2022)
grid_cv = GridSearchCV(lr, scoring = 'roc_auc', param_grid = params, cv = 5)
grid_cv.fit(train_x, train_y)
print('LogisticRegression 최적 하이퍼 파라미터: ', grid_cv.best_params_)
print('LogisticRegression 최고 예측 정확도: {:.2f}'.format(grid_cv.best_score_))
LogisticRegression 최적 하이퍼 파라미터: {'C': 1, 'penalty': 'l2'}
LogisticRegression 최고 예측 정확도: 0.86
|
cs |
> GridSearchCV를 통해서 최종 모델로 선정한 LogisticRegression의 최적의 하이퍼 파라미터를 찾는 과정이다.
> 결과로 C는 1이, penalty는 L2인 릿지규제를 가한다.
|
1
2
3
4
5
|
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(random_state=2022, C = 1, penalty = 'l2')
lr.fit(train_x, train_y)
y_pred = lr.predict(test)
|
cs |
> 찾은 하이퍼 파라미터를 넣어서 다시 학습을 시킨 후, test데이터셋을 넣어서 예측값까지 가져온다.
|
1
2
|
submission['Survived'] = y_pred
submission.to_csv('pymoon_titanic.csv', index=False)
|
cs |
> 예측값을 submission파일에 Survived변수로 삽입한 후 저장한다.
OUTTRO.
오늘은 면접을 보고 왔다.
면접 질문 중 "본인이 매출자료를 가지고 손익을 예측했을 때 유효성 검증은 어떻게 진행할 건가요?"라는 물음에 처음엔 긴장한 탓에 제대로 이해하지 못했지만, 면접관께서 이해하기 쉽게 다시 설명해 주신 다음에야 교차검증을 하겠다는 대답과 동시에 요즘 분석과제를 수행하면서 cross_val_score()을 쓰고 있다는 말을 덧붙였다. 그땐 생각나는 대로 대답했지만 이제와 생각해 보면 맞는 답이었는지, 듣고 싶었던 답이었는지 알 길이 없다.
그렇게 기분이 썩 좋지 못한 상태로 나의 약속을 지키기 위해 학습을 소홀히 하지 않기 위해 분석했었던 자료를 정리해 보았다.
'내가 하는 데이터분석 > 내가 하는 정형 분류' 카테고리의 다른 글
| [DACON] - 와인 품질 분류(분류) with Python (0) | 2022.12.16 |
|---|
